HOL Analytic Functions
- Tutorial HOL Analytic Functions
- Description Hands-On-Lab for ODTUG Kscope. The modules give examples of analytic functions in increasing complexity. If you're new to analytic functions, start at module 1 and 2 and go from there. If you know the basics already, you can jump in at module 3 or 4 if you wish.
- Area SQL Analytics
- Contributor Kim Berg Hansen
- Created Friday February 24, 2017
- Modules 6
Prerequisite SQL
/* Module 1 */ create table dept( deptno number(2) constraint pk_dept primary key , dname varchar2(14) , loc varchar2(13) ); create table emp( empno number(4) constraint pk_emp primary key , ename varchar2(10) , job varchar2(9) , mgr number(4) , hiredate date , sal number(7,2) , comm number(7,2) , deptno number(2) constraint fk_deptno references dept ); insert into dept values (10,'ACCOUNTING','NEW YORK'); insert into dept values (20,'RESEARCH','DALLAS'); insert into dept values (30,'SALES','CHICAGO'); insert into dept values (40,'OPERATIONS','BOSTON'); insert into emp values (7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,null,20); insert into emp values (7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30); insert into emp values (7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30); insert into emp values (7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,null,20); insert into emp values (7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30); insert into emp values (7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,null,30); insert into emp values (7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,null,10); insert into emp values (7788,'SCOTT','ANALYST',7566,to_date('19-04-1987','dd-mm-yyyy'),3000,null,20); insert into emp values (7839,'KING','PRESIDENT',null,to_date('17-11-1981','dd-mm-yyyy'),5000,null,10); insert into emp values (7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30); insert into emp values (7876,'ADAMS','CLERK',7788,to_date('23-05-1987', 'dd-mm-yyyy'),1100,null,20); insert into emp values (7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,null,30); insert into emp values (7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,null,20); insert into emp values (7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,null,10); commit; /* Module 2 */ create table items( item varchar2(10) primary key , grp varchar2(10) , name varchar2(20) ); create table sales ( item varchar2(10) references items (item) , mth date , qty number ); insert into items values ('101010','AUTO','Brake disc'); insert into items values ('102020','AUTO','Snow chain'); insert into items values ('103030','AUTO','Sparc plug'); insert into items values ('104040','AUTO','Oil filter'); insert into items values ('105050','AUTO','Light bulb'); insert into items values ('201010','MOBILE','Handsfree'); insert into items values ('202020','MOBILE','Charger'); insert into items values ('203030','MOBILE','iGloves'); insert into items values ('204040','MOBILE','Headset'); insert into items values ('205050','MOBILE','Cover'); insert into sales values ('101010',date '2014-04-01',10); insert into sales values ('101010',date '2014-05-01',11); insert into sales values ('101010',date '2014-06-01',12); insert into sales values ('102020',date '2014-03-01', 7); insert into sales values ('102020',date '2014-07-01', 8); insert into sales values ('103030',date '2014-01-01', 6); insert into sales values ('103030',date '2014-02-01', 9); insert into sales values ('103030',date '2014-11-01', 4); insert into sales values ('103030',date '2014-12-01',14); insert into sales values ('104040',date '2014-08-01',22); insert into sales values ('105050',date '2014-09-01',13); insert into sales values ('105050',date '2014-10-01',15); insert into sales values ('201010',date '2014-04-01', 5); insert into sales values ('201010',date '2014-05-01', 6); insert into sales values ('201010',date '2014-06-01', 7); insert into sales values ('202020',date '2014-03-01',21); insert into sales values ('202020',date '2014-07-01',23); insert into sales values ('203030',date '2014-01-01', 7); insert into sales values ('203030',date '2014-02-01', 7); insert into sales values ('203030',date '2014-11-01', 6); insert into sales values ('203030',date '2014-12-01', 8); insert into sales values ('204040',date '2014-08-01',35); insert into sales values ('205050',date '2014-09-01',13); insert into sales values ('205050',date '2014-10-01',15); commit; /* Module 3 */ create table numbers (numval) as select 1 from dual union all select 2 from dual union all select 3 from dual union all select 5 from dual union all select 6 from dual union all select 7 from dual union all select 10 from dual union all select 11 from dual union all select 12 from dual union all select 20 from dual; create table dates (dateval) as select date '2017-06-01' from dual union all select date '2017-06-02' from dual union all select date '2017-06-03' from dual union all select date '2017-06-05' from dual union all select date '2017-06-06' from dual union all select date '2017-06-07' from dual union all select date '2017-06-10' from dual union all select date '2017-06-11' from dual union all select date '2017-06-12' from dual union all select date '2017-06-20' from dual; create table gas_price_log ( logged_date date unique , logged_price number not null ); insert into gas_price_log values (date '2014-09-01', 7.50); insert into gas_price_log values (date '2014-09-02', 7.61); insert into gas_price_log values (date '2014-09-03', 7.72); insert into gas_price_log values (date '2014-09-04', 7.89); insert into gas_price_log values (date '2014-09-05', 7.89); insert into gas_price_log values (date '2014-09-06', 7.83); insert into gas_price_log values (date '2014-09-07', 7.55); insert into gas_price_log values (date '2014-09-08', 7.55); insert into gas_price_log values (date '2014-09-09', 7.72); insert into gas_price_log values (date '2014-09-10', 7.89); insert into gas_price_log values (date '2014-09-11', 7.61); insert into gas_price_log values (date '2014-09-12', 7.61); insert into gas_price_log values (date '2014-09-13', 7.61); insert into gas_price_log values (date '2014-09-14', 7.72); commit; /* Module 4+5 */ create table inventory ( item varchar2(10) -- identification of the item , loc varchar2(10) -- identification of the location , qty number -- quantity present at that location , purch date -- date that quantity was purchased ); create table orderline ( ordno number -- id-number of the order , item varchar2(10) -- identification of the item , qty number -- quantity ordered ); insert into inventory values('Ale' , '1-A-20', 18, DATE '2014-02-01'); insert into inventory values('Ale' , '1-A-31', 12, DATE '2014-02-05'); insert into inventory values('Ale' , '1-C-05', 18, DATE '2014-02-03'); insert into inventory values('Ale' , '2-A-02', 24, DATE '2014-02-02'); insert into inventory values('Ale' , '2-D-07', 9, DATE '2014-02-04'); insert into inventory values('Bock', '1-A-02', 18, DATE '2014-02-06'); insert into inventory values('Bock', '1-B-11', 4, DATE '2014-02-05'); insert into inventory values('Bock', '1-C-04', 12, DATE '2014-02-03'); insert into inventory values('Bock', '1-B-15', 2, DATE '2014-02-02'); insert into inventory values('Bock', '2-D-23', 1, DATE '2014-02-04'); insert into orderline values (42, 'Ale' , 24); insert into orderline values (42, 'Bock', 18); insert into orderline values (51, 'Ale' , 24); insert into orderline values (51, 'Bock', 18); insert into orderline values (62, 'Ale' , 8); insert into orderline values (73, 'Ale' , 16); insert into orderline values (73, 'Bock', 6); commit; /* Module 6 */ create table monthly_sales ( item varchar2(10) , mth date , qty number ); insert into monthly_sales values ('Snowchain', date '2011-01-01', 79); insert into monthly_sales values ('Snowchain', date '2011-02-01', 133); insert into monthly_sales values ('Snowchain', date '2011-03-01', 24); insert into monthly_sales values ('Snowchain', date '2011-04-01', 1); insert into monthly_sales values ('Snowchain', date '2011-05-01', 0); insert into monthly_sales values ('Snowchain', date '2011-06-01', 0); insert into monthly_sales values ('Snowchain', date '2011-07-01', 0); insert into monthly_sales values ('Snowchain', date '2011-08-01', 0); insert into monthly_sales values ('Snowchain', date '2011-09-01', 1); insert into monthly_sales values ('Snowchain', date '2011-10-01', 4); insert into monthly_sales values ('Snowchain', date '2011-11-01', 15); insert into monthly_sales values ('Snowchain', date '2011-12-01', 74); insert into monthly_sales values ('Snowchain', date '2012-01-01', 148); insert into monthly_sales values ('Snowchain', date '2012-02-01', 209); insert into monthly_sales values ('Snowchain', date '2012-03-01', 30); insert into monthly_sales values ('Snowchain', date '2012-04-01', 2); insert into monthly_sales values ('Snowchain', date '2012-05-01', 0); insert into monthly_sales values ('Snowchain', date '2012-06-01', 0); insert into monthly_sales values ('Snowchain', date '2012-07-01', 0); insert into monthly_sales values ('Snowchain', date '2012-08-01', 1); insert into monthly_sales values ('Snowchain', date '2012-09-01', 0); insert into monthly_sales values ('Snowchain', date '2012-10-01', 3); insert into monthly_sales values ('Snowchain', date '2012-11-01', 17); insert into monthly_sales values ('Snowchain', date '2012-12-01', 172); insert into monthly_sales values ('Snowchain', date '2013-01-01', 167); insert into monthly_sales values ('Snowchain', date '2013-02-01', 247); insert into monthly_sales values ('Snowchain', date '2013-03-01', 42); insert into monthly_sales values ('Snowchain', date '2013-04-01', 0); insert into monthly_sales values ('Snowchain', date '2013-05-01', 0); insert into monthly_sales values ('Snowchain', date '2013-06-01', 0); insert into monthly_sales values ('Snowchain', date '2013-07-01', 0); insert into monthly_sales values ('Snowchain', date '2013-08-01', 1); insert into monthly_sales values ('Snowchain', date '2013-09-01', 0); insert into monthly_sales values ('Snowchain', date '2013-10-01', 1); insert into monthly_sales values ('Snowchain', date '2013-11-01', 73); insert into monthly_sales values ('Snowchain', date '2013-12-01', 160); insert into monthly_sales values ('Sunshade' , date '2011-01-01', 4); insert into monthly_sales values ('Sunshade' , date '2011-02-01', 6); insert into monthly_sales values ('Sunshade' , date '2011-03-01', 32); insert into monthly_sales values ('Sunshade' , date '2011-04-01', 45); insert into monthly_sales values ('Sunshade' , date '2011-05-01', 62); insert into monthly_sales values ('Sunshade' , date '2011-06-01', 58); insert into monthly_sales values ('Sunshade' , date '2011-07-01', 85); insert into monthly_sales values ('Sunshade' , date '2011-08-01', 28); insert into monthly_sales values ('Sunshade' , date '2011-09-01', 24); insert into monthly_sales values ('Sunshade' , date '2011-10-01', 19); insert into monthly_sales values ('Sunshade' , date '2011-11-01', 6); insert into monthly_sales values ('Sunshade' , date '2011-12-01', 8); insert into monthly_sales values ('Sunshade' , date '2012-01-01', 2); insert into monthly_sales values ('Sunshade' , date '2012-02-01', 13); insert into monthly_sales values ('Sunshade' , date '2012-03-01', 29); insert into monthly_sales values ('Sunshade' , date '2012-04-01', 60); insert into monthly_sales values ('Sunshade' , date '2012-05-01', 29); insert into monthly_sales values ('Sunshade' , date '2012-06-01', 78); insert into monthly_sales values ('Sunshade' , date '2012-07-01', 56); insert into monthly_sales values ('Sunshade' , date '2012-08-01', 22); insert into monthly_sales values ('Sunshade' , date '2012-09-01', 11); insert into monthly_sales values ('Sunshade' , date '2012-10-01', 13); insert into monthly_sales values ('Sunshade' , date '2012-11-01', 5); insert into monthly_sales values ('Sunshade' , date '2012-12-01', 3); insert into monthly_sales values ('Sunshade' , date '2013-01-01', 2); insert into monthly_sales values ('Sunshade' , date '2013-02-01', 8); insert into monthly_sales values ('Sunshade' , date '2013-03-01', 28); insert into monthly_sales values ('Sunshade' , date '2013-04-01', 26); insert into monthly_sales values ('Sunshade' , date '2013-05-01', 23); insert into monthly_sales values ('Sunshade' , date '2013-06-01', 46); insert into monthly_sales values ('Sunshade' , date '2013-07-01', 73); insert into monthly_sales values ('Sunshade' , date '2013-08-01', 25); insert into monthly_sales values ('Sunshade' , date '2013-09-01', 13); insert into monthly_sales values ('Sunshade' , date '2013-10-01', 11); insert into monthly_sales values ('Sunshade' , date '2013-11-01', 3); insert into monthly_sales values ('Sunshade' , date '2013-12-01', 5); commit; /* === */ alter session set nls_date_format = 'YYYY-MM-DD';
The Basics
The basis of this module is the EMP table of the SCOTT sample schema, particularly these columns.
select deptno , ename , sal from emp order by deptno , sal;Most aggregate functions exist in an analytic variant too. The analytic function call is characterized by the keyword OVER followed by a set of parentheses, optionally containing one or more of three different analytic clauses.


In the simplest form an empty set of parentheses can be used after OVER, signifying the function is to be applied on all rows of the output. For example using the SUM function to produce a grand total of salaries. (Or try using COUNT or AVG or other functions.)
select deptno , ename , sal , sum(sal) over () sum_sal from emp order by deptno , sal;The first analytic clause is PARTITION BY. Similar to GROUP BY for aggregate functions, the PARTITION BY clause for analytic functions can be used to signify the function is to be applied to groups (partitions) of data. For the SUM function creating subtotals by for example department. (Or try partitioning by JOB or other columns.)
select deptno , ename , sal , sum(sal) over ( partition by deptno ) sum_sal from emp order by deptno , sal;The other two analytic clauses are the ORDER BY clause and the so-called WINDOWING clause. The WINDOWING clause specifies a "window" of rows (relative to the current row of the output) for the function, like for example the window ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWS. That window specifies to calculate the function on the rows from the start (unbounded) until the current row - and to give meaning to what is the "start" you use the ORDER BY clause to give the rows an ordering (otherwise the ordering is indeterminate and the "start" could be any row.) With an ORDER BY and the mentioned windowing clause used on the SUM function we get a running total.
select deptno , ename , sal , sum(sal) over ( order by sal rows between unbounded preceding and current row ) sum_sal from emp order by sal;In the example above, the ORDER BY in the analytic clause and the ORDER BY of the query itself is identical, but they need not be. You can have the ordering (and thereby windowing) of the analytic clause be completely different from the final query ORDER BY. (Try different combinations and observe the results.)
select deptno , ename , sal , sum(sal) over ( order by sal rows between unbounded preceding and current row ) sum_sal from emp order by deptno , sal;All three analytic clauses can be combined if you wish, for example using PARTITION BY to execute the analytics separately for each DEPTNO, which then makes the running total work inside each partition, so the "start row" (unbounded preceding) is the row with the lowest salary within each department. The running total is performed completely separately for each partition.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal rows between unbounded preceding and current row ) sum_sal from emp order by deptno , sal;The windowing clause can be specified very detailed allowing much more complex windows than a simple running total. Rows can be specified with a certain offset either PRECEDING or FOLLOWING, or the offset may be UNBOUNDED in either direction, or CURRENT ROW is specified. For example a slight variation of the running total can be to replace CURRENT ROW with 1 PRECEDING, which means to calculate the function on all rows from the "start" and up to and including the row before the current row - in other words a total of all previous rows.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal rows between unbounded preceding and 1 preceding ) sum_sal from emp order by deptno , sal;The previous examples have all used PRECEDING to specify a window of rows that came before the current row in the ordering. We can also "look ahead" to rows that come after the current row by using FOLLOWING, for example a kind of "reversed" running total.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal rows between current row and unbounded following ) sum_sal from emp order by deptno , sal;With FOLLOWING we can also use an offset rather than CURRENT ROW, so we for example can calculate the total for all the rows yet to come.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal rows between 1 following and unbounded following ) sum_sal from emp order by deptno , sal;It is also allowed a window that is unbounded in both ends, like this example. But it is not really sensible, as the result is identical to skipping the ORDER BY and the windowing clauses alltogether.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal rows between unbounded preceding and unbounded following ) sum_sal from emp order by deptno , sal;The window can also be spefied with offset bounds both for the start and the end of the window. The start and end bounds may both be either preceding or following, or you can have the start be preceding and the end following to get for example a total sum of the previous row, the current row and the following row. (Try different offsets, either preceding or following.)
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal rows between 1 preceding and 1 following ) sum_sal from emp order by deptno , sal;When we use ROWS BETWEEN, the offset used for PRECEDING and FOLLOWING specifies a number of rows in the output. If you are using a single column in the ORDER BY clause and it is numeric or date/timestamp, you can instead use RANGE BETWEEN. Using RANGE BETWEEN the window is not specified counting rows, but instead the window is those rows who have a value in the ordering column that is the specified offset less than or greater than the value in the current row. For example we can have a total of salaries for those who earn between 500 less and 500 more than the employee in the current row.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal range between 500 preceding and 500 following ) sum_sal from emp order by deptno , sal;Just like ROWS BETWEEN, RANGE windows also do not need to include the current row. The window is always relative to the current row, but it may be specified for example as those who earn between 300 more and 3000 more than the employee in the current row.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal range between 300 following and 3000 following ) sum_sal from emp order by deptno , sal;When you specify RANGE BETWEEN and use CURRENT ROW, then CURRENT ROW actually means rows with the same value in the ordering column. This means that if we do the running total using RANGE instead of ROWS, the analytic function output can include data from "following" rows if they have the same value - even though CURRENT ROW was specified as the end of the window.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal range between unbounded preceding and current row ) sum_sal from emp order by deptno , sal;It is easier to see what happens if we make two running totals side by side - one with RANGE and one with ROWS. Look at employees that earn the same (within same department) - you'll see the difference between RANGE and ROWS for SCOTT/FORD and MARTIN/WARD.
select deptno , ename , sal , sum(sal) over ( partition by deptno order by sal range between unbounded preceding and current row ) range_sal , sum(sal) over ( partition by deptno order by sal rows between unbounded preceding and current row ) rows_sal from emp order by deptno , sal;The windowing clause needs not be specified. But if you use an ORDER BY clause without any windowing clause (for functions that support windowing clause, some do not), then the default windowing clause is RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, as you can observe by comparing the two explicit windowing clauses with no windowing clause.
select deptno, ename, sal , sum(sal) over ( partition by deptno order by sal range between unbounded preceding and current row ) range_sal , sum(sal) over ( partition by deptno order by sal rows between unbounded preceding and current row ) rows_sal , sum(sal) over ( partition by deptno order by sal /* no window - rely on default */ ) def_sal from emp order by deptno , sal;As a large majority of use cases for analytic functions call for ROWS BETWEEN, a best practice is that whenever you use an ORDER BY clause, then also always use an explicit windowing clause (most often ROWS and once in a while RANGE) even if it happens to match the default.
Another best practice is to ensure consistent results for ROWS BETWEEN by using a column combination for ORDER BY that is unique (within the partition, if any). Many of the examples above using an ordering of SAL together with ROWS BETWEEN could potentially return different results between calls, because it would be indeterminate whether SCOTT or FORD was first in the ordering. So SCOTT could be included in the running total of FORD or vice versa. By adding EMPNO to the ORDER BY, we ensure consistent results.
select deptno, empno, ename, sal , sum(sal) over ( partition by deptno order by sal, empno rows between unbounded preceding and current row ) sum_sal from emp order by deptno , sal , empno;You now know the basics of the three analytic clauses within OVER () - the partitioning, ordering and windowing clauses. You can play around with changing the examples above and observe the effects.
TOP-N and Ratios
The basis of this module is a table of items, each item within an item group GRP.
select * from items order by grp, item;And a table of monthly sales quantities for each item.
select * from sales order by item, mth;The base query for our TOP-N calculation is a classic join with group by to get the sales quantity for each item in the year 2014. That will be the basis for determining a TOP-3 best selling items within each item group.
select i.grp, i.item, max(i.name) name, sum(s.qty) qty from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item order by i.grp, sum(s.qty) desc, i.item;For TOP-N we can use three different analytic functions, DENSE_RANK, RANK and ROW_NUMBER. All three assigns integer numbers to the rows in the ordering specified by the ORDER BY analytic clause - the difference is how they handle ties (duplicates) in the order:
- DENSE_RANK assigns the same rank to ties and the next rank will be 1 higher (i.e. ranks will be consecutive without gaps.)
- RANK also assigns the same rank to ties, but the next rank will then be incremented by the number of tied rows rather than 1 (i.e. there will be gaps in the ranks where there are ties, just like how the olympics assign medals.)
- ROW_NUMBER never assigns the same number to any rows, it simply assigns consecutive numbers according to the ordering specified, so if there are for example 2 rows tied for 3rd place, it will be indeterminate which row gets number 3 and which gets number 4. (Therefore a best practice for ROW_NUMBER is to make the ordering unique within each partition to ensure consistent results.)
So we can take our base GROUP BY query in an inline view and then calculate all three analytic functions on the result and compare them to see how the ties are handled by each function.select g.grp, g.item, g.name, g.qty , dense_rank() over ( partition by g.grp order by g.qty desc ) drnk , rank() over ( partition by g.grp order by g.qty desc ) rnk , row_number() over ( partition by g.grp order by g.qty desc, g.item ) rnum from ( select i.grp, i.item, max(i.name) name, sum(s.qty) qty from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item ) g order by g.grp, g.qty desc, g.item;It is possible to avoid the inline view in this case, because analytic functions are evaluated almost at the very end of subquery evaluation (normally just before the final ORDER BY.) That means that the WHERE, GROUP BY and HAVING clauses of a query (and thus all aggregates) are evaluated before the analytic functions are applied. Hence we can make a query with a GROUP BY clause and aggregate functions, and in the select list we can use analytic functions that within the various analytic clauses can use all the grouped columns as well as aggregates (the same expressions that we can SELECT in a GROUP BY query.) So for example we can use the aggregate expression SUM(S.QTY) in the ORDER BY clause of our analytic functions.
select i.grp, i.item, max(i.name) name, sum(s.qty) qty , dense_rank() over ( partition by i.grp order by sum(s.qty) desc ) drnk , rank() over ( partition by i.grp order by sum(s.qty) desc ) rnk , row_number() over ( partition by i.grp order by sum(s.qty) desc, i.item ) rnum from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item order by i.grp, sum(s.qty) desc, i.item;But since the analytic functions are evaluated almost at the end of query evaluation, that also means analytic functions are not allowed within for example the WHERE clause. This query may look like it queries a TOP-3, but it is syntactically wrong and will raise error: ORA-30483: window functions are not allowed here.
select i.grp, i.item, max(i.name) name, sum(s.qty) qty , rank() over ( partition by i.grp order by sum(s.qty) desc ) rnk from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' and rank() over ( /* Raises ORA-30483 */ partition by i.grp order by sum(s.qty) desc ) <= 3 group by i.grp, i.item order by i.grp, sum(s.qty) desc, i.item;So instead we have to wrap the query with the analytic functions inside an inline view and then filter with WHERE on the results of the inline view. This is very classic when you work with analytic functions and you can easily create a query with several layers of inline views. (Therefore it can also be nice to use techniques like this one where we do analytic functions directly on aggregates to avoid more inline views than we have to - not that it matters to performance, it is mostly about readability when the queries become large.)
So here we can see a TOP-3 query using RANK - RANK being equivalent to olympic ranking in that when we have 2 gold medals (rank 1) we skip the silved medal and then number 3 will get a bronze medal. Observe that using RANK a TOP-3 may return more than 3 rows as the top 3, that can happen if there are ties for bronze medal or if there are more than 3 tied for gold medal.
select g.grp, g.item, g.name, g.qty, g.rnk from ( select i.grp, i.item, max(i.name) name, sum(s.qty) qty , rank() over ( partition by i.grp order by sum(s.qty) desc ) rnk from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item ) g where g.rnk <= 3 order by g.grp, g.rnk, g.item;Using DENSE_RANK for TOP-3 can also (and in more cases than RANK) return more than 3 rows, as you can see when comparing the results of this query with the previous one.
select g.grp, g.item, g.name, g.qty, g.rnk from ( select i.grp, i.item, max(i.name) name, sum(s.qty) qty , dense_rank() over ( partition by i.grp order by sum(s.qty) desc ) rnk from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item ) g where g.rnk <= 3 order by g.grp, g.rnk, g.item;Using ROW_NUMBER on the other hand will never return more than 3 rows for a TOP-3, as ties are never assigned the same number. But it also means that of two items that sold the same (iGloves and Cover), only one will be in the output. Which one it will be is indeterminate, so the ensure we always get consistent results it is a good idea to add something to the ORDER BY (in this case I.ITEM) to make it unique and therefore determinate results, otherwise a user might run the report and get iGloves included sometimes and Cover other times, which users will tend to see as a bug (even if both results are correct.)
select g.grp, g.item, g.name, g.qty, g.rnk from ( select i.grp, i.item, max(i.name) name, sum(s.qty) qty , row_number() over ( partition by i.grp order by sum(s.qty) desc, i.item ) rnk from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item ) g where g.rnk <= 3 order by g.grp, g.rnk, g.item;We would like to add to the TOP-3 report a couple columns showing for the top items how great a percentage the item sales is out of the item group total sales respectively out of the grand total sales. That is not hard to do using two analytic SUM function calls - one using PARTITION BY to get the item group total, one using the empty () to get the grand total. Again here we take advantage of the fact that aggregates can be used within analytics, so the "nested" SUM calls are an aggregate SUM within an analytic SUM.
select g.grp, g.item, g.name, g.qty, g.rnk , round(g.g_pct,1) g_pct , round(g.t_pct,1) t_pct from ( select i.grp, i.item, max(i.name) name, sum(s.qty) qty , rank() over ( partition by i.grp order by sum(s.qty) desc ) rnk , 100 * sum(s.qty) / sum(sum(s.qty)) over (partition by i.grp) g_pct , 100 * sum(s.qty) / sum(sum(s.qty)) over () t_pct from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item ) g where g.rnk <= 3 order by g.grp, g.rnk, g.item;But there is an easier way rather than taking the row value and divide by the SUM total, we can instead simply use the analytic RATIO_TO_REPORT function, which calculates the desired ratio in a single call rather than doing the division manually. It helps the code being self-documenting as the function name clearly states what we are calculating. Also it helps for those (very rare border-line) cases where the sum total becomes negative (if we are summing values that can be both negative and positive), where the division would raise an error but RATIO_TO_REPORT just becomes NULL to signify the ratio is indeterminate in such cases.
select g.grp, g.item, g.name, g.qty, g.rnk , round(g.g_pct,1) g_pct , round(g.t_pct,1) t_pct from ( select i.grp, i.item, max(i.name) name, sum(s.qty) qty , rank() over ( partition by i.grp order by sum(s.qty) desc ) rnk , 100 * ratio_to_report(sum(s.qty)) over (partition by i.grp) g_pct , 100 * ratio_to_report(sum(s.qty)) over () t_pct from items i join sales s on s.item = i.item where s.mth between date '2014-01-01' and date '2014-12-01' group by i.grp, i.item ) g where g.rnk <= 3 order by g.grp, g.rnk, g.item;You now have the techniques for creating TOP-N queries of the three different types. When your users ask you to develop a TOP-N query, be sure to ask them how they want ties handled, as that will determine which ranking function you want to use.
Note: In Oracle version 12.1 came a shorter notation for doing TOP-N queries, where you do not need analytic functions and inline views but simply can add FETCH FIRST 3 ROWS ONLY or FETCH FIRST 3 ROWS WITH TIES. This FETCH FIRST syntax executes analytic functions and filters on them behind the scenes, just like the queries in this module. FETCH FIRST syntax supports two methods with the same results as using ROW_NUMBER or RANK, but if you want DENSE_RANK results, you still need to do it manually like shown here. Also FETCH FIRST cannot do PARTITION BY, it can only do a TOP-3 for all items, not a TOP-3 within each group (partition). So queries like these are still often needed.
Group Consecutive Data
The basis of this module is three different tables. First we'll look at a simple table of numbers.
select * from numbers order by numval;The task is to group these numbers such that consecutive numbers are grouped together, while wherever there is a "gap" in the numbers, a new group is started. One way to do this is the socalled "Tabibitosan" method, which simply compares the number values with a truly consecutive number (such as can be generated with analytic function ROW_NUMBER) - as long as the difference is identical, the tested number values are consecutive (just like the generated ROW_NUMBER values), but where there is a "gap", the difference increases. We can use this difference as a GRP column.
select numval , row_number() over (order by numval) as rn , numval - row_number() over (order by numval) as grp from numbers order by numval;Then we simply wrap in an inline view and GROUP BY the GRP column, and we get the desired grouping.
select min(numval) firstval , max(numval) lastval , count(*) cnt , grp from ( select numval , numval-row_number() over (order by numval) as grp from numbers ) group by grp order by firstval;This method can be adapted to other things than just integer numbers increasing by 1. For example let us look at a simple table of dates.
select * from dates order by dateval;All we need is to create an expression that returns an integer number that should increase by 1 to meet "consecutive" criteria. In this case that can simply be done by subtracting a fixed DATE literal from the date value, since that returns a numeric value where "1" equals one day. As long as we can create some integer expression with a scale of 1, we can apply Tabibitosan method by subtracting ROW_NUMBER.
select dateval , row_number() over (order by dateval) as rn , (dateval - date '2016-01-01') - row_number() over (order by dateval) as grp from dates order by dateval;And again this can simply be used in a GROUP BY.
select min(dateval) firstval , max(dateval) lastval , count(*) cnt , grp from ( select dateval , (dateval - date '2016-01-01') - row_number() over (order by dateval) as grp from dates ) group by grp order by firstval;Sometimes it is not so much "gaps" in the consecutive data we are after, but rather consecutive data where we wish to group rows that have identical values in another column, as long as they are consecutive. When a non-identical value appears, we start a new group. If the original value appears again later, this is a new group, as it was not consecutive with the previous appearances. To examine methods for this, we use a table that stores daily gasoline prices (in Danish Kroner per Liter) every day.
select * from gas_price_log order by logged_date;We want to group rows of consecutive days with identical prices. Multiple methods can be used for this.
The first method we start by using LAG in a CASE statement to make a column PERIOD_START. It will contain the period start date for those rows where the price is different than the previous row (this is the beginning of each group), while those rows that have same price as the previous date get NULL value.
select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then null else logged_date end period_start from gas_price_log order by logged_date;We can fill out the NULL values in PERIOD_START by using LAST_VALUE with IGNORE NULLS. This "carries down" the PERIOD_START value downwards as long as there are NULLs.
select logged_date , logged_price , period_start , last_value(period_start ignore nulls) over ( order by logged_date rows between unbounded preceding and current row ) period_group from ( select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then null else logged_date end period_start from gas_price_log ) order by logged_date;Then if we want it, we can create a nice numeric "group id" with DENSE_RANK as a "reporting friendly" way of display rather than PERIOD_GROUP.
select logged_date , logged_price , period_start , period_group , dense_rank() over ( order by period_group ) logged_group_id from ( select logged_date , logged_price , period_start , last_value(period_start ignore nulls) over ( order by logged_date rows between unbounded preceding and current row ) period_group from ( select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then null else logged_date end period_start from gas_price_log ) ) order by logged_date;Or of course we can GROUP BY the PERIOD_GROUP to show the rows in a grouped fashion.
select min(logged_date) start_date , max(logged_date) end_date , count(*) days , min(logged_price) logged_price from ( select logged_date , logged_price , period_start , last_value(period_start ignore nulls) over ( order by logged_date rows between unbounded preceding and current row ) period_group from ( select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then null else logged_date end period_start from gas_price_log ) ) group by period_group order by start_date;An alternative to using LAG to create the PERIOD_START column with NULLs in it (and filling the NULLs afterwards), is to use the LAG in CASE comparison to create a column specifying 1 if the row price is identical to the previous row, and 0 otherwise.
select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then 1 else 0 end identical from gas_price_log order by logged_date;Then we apply a kind of "reverse Tabibitosan". The rolling sum of the "identical" column increases by 1 whenever the row has identical price to the previous one. Which means that if we subtract that rolling sum from the consecutive numbers generated by ROW_NUMBER, we get a new number whenever the rolling sum is not increasing, and the same number whenever the rolling sum is increasing. The result is a nice numeric group id just like we got above with DENSE_RANK.
select logged_date , logged_price , identical , sum(identical) over ( order by logged_date rows between unbounded preceding and current row ) sum_identical , row_number() over ( order by logged_date ) - sum(identical) over ( order by logged_date rows between unbounded preceding and current row ) logged_group_id from ( select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then 1 else 0 end identical from gas_price_log ) order by logged_date;But this numeric method can be simplified by reversing the logic. Rather than the IDENTICAL column, which had a 1 value for identically priced rows, we can turn it around with a NON_IDENTICAL column, which has a 1 value for rows that are not identically priced.
select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then 0 else 1 end non_identical from gas_price_log order by logged_date;This enables us simply to get the desired group id by a simple rolling sum of the NON_IDENTICAL column. You can think of NON_IDENTICAL as being a marker for whenever there has been a change in the value, and the rolling sum then becomes a "count of changes so far". Where the prices are identical, the "count of changes" does not increase.
select logged_date , logged_price , non_identical , sum(non_identical) over ( order by logged_date rows between unbounded preceding and current row ) logged_group_id from ( select logged_date , logged_price , case lag(logged_price) over (order by logged_date) when logged_price then 0 else 1 end non_identical from gas_price_log ) order by logged_date;Most importantly this module has shown that you can use multiple methods to achieve the same results. Tabibitosan and the last query of summing "change markers" are quite efficient, but the alternatives might be good approaches for different use cases. Keep an open mind and try out different approaches to your problems, as different solutions may exists - some more efficient than others.
FIFO Picking
The basis of this module is a table containing inventory of items - how big a quantity of each item is located at each location in the warehouse and when was that particular quantity purchased.
select * from inventory order by item, loc;Location codes consists of three parts - warehouse, aisle and position - in the 2 warehouses shown here.

Also we have a table of orderlines specifying for each order how many of each item we must deliver to the customer.
select * from orderline order by ordno, item;The forklift operator in the warehouse needs to pick the items for delivering one of the orders, order number 42, but as the items have a limited shelf-life he needs to pick from the oldest quantities first (the principle of FIFO: First-In-First-Out.)
If we join the orderlines to the inventory and order each item by the purchase date, we can visually easily see that he needs to pick from the locations with the oldest quantities and move on the the second-oldest and continue until he has picked the quantity ordered.
select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 order by o.item, i.purch, i.loc;The trick is now to build a query to perform what we easily can see visually. Keep picking (adding quantities) until a certain quantity is reached sounds rather like doing a running total until it reaches a desired total. Let us try doing a running total.
select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ) sum_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 order by o.item, i.purch, i.loc;And then we can try keeping only those rows where the running total is less than the desired ordered quantity - will that give us the desired result?
select s.* from ( select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ) sum_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_qty < s.ord_qty order by s.item, s.purch, s.loc;Nope, it did not work. The problem being that the location quantity of the row where the desired total is reached is included in the running total of that row, so our WHERE clause filters away the last row of the rows we need.
What we need is a running total of all the previous rows, which is easy with analytic functions, just change the windowing clauses to use 1 PRECEDING.
select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 order by o.item, i.purch, i.loc;Now we can do a WHERE clause that keeps all rows where the sum of the previous rows is less than the ordered quantity. This means that when the previous rows running total is greater than or equal to the ordered quantity, then the current row is not needed for the picking and is filtered away. Note we use an NVL to make the first SUM_PRV_QTY value 0 instead of null.
The quantity our operator needs to pick at each location is then either all of the location quantity or the quantity not yet picked (ordered qty minus the previous running total), whichever is the smallest.
select s.* , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.item, s.purch, s.loc;During development of the query, we've kept selecting all the columns - now we can clean up the query a bit and only keep the necessary columns to be shown to the operator as a picking list, which we order by location rather than the item/purchase date order we've used before.
select s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.loc;Taking advantage of how the analytic ORDER BY can be different than the final query ORDER BY, we can switch the principles of picking just by changing the analytic ORDER BY. For example instead of FIFO principle, we can choose inventory quantities based on location order - always try to find the nearest locations for fastest picking.
select s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.loc -- << only line changed rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.loc;Or we can choose inventory quantities by locations with the largest quantities first - which will yield the smallest number of picks to be performed (but then leave a lot of small quantities scattered in the warehouse for later picking.)
select s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.qty desc, i.loc -- << only line changed rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.loc;Or we can use a space optimizing principle of cleaning out small quantities first - that way we'll free most locations for use by other items (but then have to drive a lot around in the warehouse to perform many picks.)
select s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.qty, i.loc -- << only line changed rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.loc;Now we know how to pick an order by FIFO or other principle in a single SQL statement in location order. But location order is not really the most efficient way for our operator to drive his forklift. He would work more efficiently if the picking list was ordered such, that the picks in the first aisle in the warehouse he needs to visit will be ordered in one direction, the picks in the second aisle he needs to visit will be ordered in the other direction, and so on, switching directions every other aisle he visits.
To demonstrate doing that, we'll use the picking principle of cleaning out small quantities first rather than FIFO, as it gives us the most locations to visit, thus demonstrating the results most clearly.
The location code in the inventory table is split into 3 parts - warehouse number, aisle letter, and position number (in true use cases you might get that information from a lookup table based on a location pseudo primary key.)
select to_number(substr(s.loc,1,1)) warehouse , substr(s.loc,3,1) aisle , to_number(substr(s.loc,5,2)) position , s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.qty, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.loc;Showing those results in the warehouse, we can see that location order is not the optimal way.

Within an analytic DENSE_RANK call we can use an ORDER BY containing warehouse and aisle. This means that "ties" (rows with identical values for warehouse and aisle) will get the same rank. And since we use DENSE_RANK instead of RANK, the ranking numbers will be consecutive. So column AISLE_NO will number the aisles our operation has to visit with numbers 1, 2, 3...
select to_number(substr(s.loc,1,1)) warehouse , substr(s.loc,3,1) aisle , dense_rank() over ( order by to_number(substr(s.loc,1,1)) -- warehouse , substr(s.loc,3,1) -- aisle ) aisle_no , to_number(substr(s.loc,5,2)) position , s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.qty, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty order by s.loc;Wrapping the DENSE_RANK calculation in an inline view enables us to use the AISLE_NO column in the final ORDER BY clause, where we then can order the picks in odd-numbered aisles (1,3,...) by position ascending and even-numbered aisles (2,4,...) by position descending.
select s2.warehouse, s2.aisle, s2.aisle_no, s2.position, s2.loc, s2.item, s2.pick_qty from ( select to_number(substr(s.loc,1,1)) warehouse , substr(s.loc,3,1) aisle , dense_rank() over ( order by to_number(substr(s.loc,1,1)) -- warehouse , substr(s.loc,3,1) -- aisle ) aisle_no , to_number(substr(s.loc,5,2)) position , s.loc, s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.qty, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty ) s2 order by s2.warehouse , s2.aisle_no , case when mod(s2.aisle_no,2) = 1 then s2.position else -s2.position end;And now with the use of DENSE_RANK our forklift driver will be shown a much more efficient route.

Supposing the two warehouses do not have doors between them at both end of the aisles, but only one door at one end, then we need the AISLE_NO count to "restart" in the second warehouse, so the first aisle visited in the second warehouse always will be odd-numbered (1) rather than either odd or even depending on how many aisles he visits in the first warehouse.
That is easily accomplished in the DENSE_RANK analytic clauses - instead of having both warehouse and aisle in the ORDER BY clause, we PARTITION by warehouse and ORDER BY aisle. Then the ranking is performed individually for each warehouse.select s2.warehouse, s2.aisle, s2.aisle_no, s2.position, s2.loc, s2.item, s2.pick_qty from ( select to_number(substr(s.loc,1,1)) warehouse , substr(s.loc,3,1) aisle , dense_rank() over ( partition by to_number(substr(s.loc,1,1)) -- warehouse order by substr(s.loc,3,1) -- aisle ) aisle_no , to_number(substr(s.loc,5,2)) position , s.loc, s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.qty, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderline o join inventory i on i.item = o.item where o.ordno = 42 ) s where s.sum_prv_qty < s.ord_qty ) s2 order by s2.warehouse , s2.aisle_no , case when mod(s2.aisle_no,2) = 1 then s2.position else -s2.position end;With the PARTITION BY in the DENSE_RANK function, we easily get a better route for this warehouse layout too.

You have now seen step by step the development of a query that using two analytic functions (SUM and DENSE_RANK) solve a problem efficiently in SQL that without analytic functions would either be very hard and inefficient or need a slow procedural approach.
In the next module we'll continue adding more to this FIFO picking query to show how to go even further in SQL complexity.
FIFO Batch Picking
This continues the previous module, based on the same tables.
So far our forklift operator has picked a single order (order number 42) - now we would like to use him more efficiently and have him batch-pick multiple orders simultaneously, for example order numbers 51, 62 and 73.
For a first shot at the query needed, we can simply group the desired order numbers by item giving us the total quantities of each item we need to pick. This aggregated dataset we can pass to the FIFO picking query and get a picking list just as if it was a single order.
with orderbatch as ( select o.item, sum(o.qty) qty from orderline o where o.ordno in (51, 62, 73) group by o.item ) select s.loc , s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty from orderbatch o join inventory i on i.item = o.item ) s where s.sum_prv_qty < s.ord_qty order by s.loc;This gives us the correct total amount to be picked at each location, which is OK as such, but the operator cannot tell how much of each pick he should pack with each order. We need to add something more for this.
First we can add another rolling sum SUM_QTY besides our SUM_PRV_QTY, with SUM_QTY including the current row (while SUM_PRV_QTY only has the previous rows.) SUM_QTY could also have been calculated as SUM_PRV_QTY + LOC_QTY, but as this is an analytic function tutorial, we'll use the two analytic calls just to demonstrate the difference in windowing clauses.
Using the two rolling sums, we get the FROM_QTY and TO_QTY that specifies, that out of the total 48 ALE we need to pick, in the first location we pick number 1 to 18, in the second location we pick number 19 to 42, and so on. These intervals we can use later on.
with orderbatch as ( select o.item, sum(o.qty) qty from orderline o where o.ordno in (51, 62, 73) group by o.item ) select s.loc, s.item , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty , sum_prv_qty + 1 from_qty , least(sum_qty, ord_qty) to_qty from ( select o.item, o.qty ord_qty, i.purch, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ),0) sum_qty from orderbatch o join inventory i on i.item = o.item ) s where s.sum_prv_qty < s.ord_qty order by s.item, s.purch, s.loc;Similar to calculating the intervals that each location represents out of the total picked quantity of an item, so we can calculate intervals that each order represents of the total. Using the same technique with two running totals each with a different windowing clause, we see that out of the total 48 ALE, the first order receives number 1 to 24, the second order receives number 25 to 32, and so on.
select o.ordno, o.item, o.qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and 1 preceding ),0) + 1 from_qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and current row ),0) to_qty from orderline o where ordno in (51, 62, 73) order by o.item, o.ordno;Having these two sets of quantity intervals calculated, we can join on "overlapping" intervals. -- Now join on "overlapping" qty intervals
with orderlines as ( select o.ordno, o.item, o.qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and 1 preceding ),0) + 1 from_qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and current row ),0) to_qty from orderline o where ordno in (51, 62, 73) ), orderbatch as ( select o.item, sum(o.qty) qty from orderlines o group by o.item ), fifo as ( select s.loc, s.item, s.purch , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty , sum_prv_qty + 1 from_qty , least(sum_qty, ord_qty) to_qty from ( select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ),0) sum_qty from orderbatch o join inventory i on i.item = o.item ) s where s.sum_prv_qty < s.ord_qty ) select f.loc, f.item, f.purch, f.pick_qty, f.from_qty f_from_qty, f.to_qty f_to_qty , o.ordno, o.qty, o.from_qty o_from_qty, o.to_qty o_to_qty from fifo f join orderlines o on o.item = f.item and o.to_qty >= f.from_qty and o.from_qty <= f.to_qty order by f.item, f.purch, o.ordno;Looking at the joined intervals, we can see that the 18 ALE picked in the first location all go to the first order. The 24 we pick in the second location overlaps with all three order quantity intervals, so the first order get 6 of the 24, the second order get 8 of the 24, and the third order get the last 10. Using LEAST and GREATEST we can calculate this overlap as column PICK_ORD_QTY.
with orderlines as ( select o.ordno, o.item, o.qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and 1 preceding ),0) + 1 from_qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and current row ),0) to_qty from orderline o where ordno in (51, 62, 73) ), orderbatch as ( select o.item, sum(o.qty) qty from orderlines o group by o.item ), fifo as ( select s.loc, s.item, s.purch, s.loc_qty , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty , sum_prv_qty + 1 from_qty , least(sum_qty, ord_qty) to_qty from ( select o.item, o.qty ord_qty, i.loc, i.purch, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ),0) sum_qty from orderbatch o join inventory i on i.item = o.item ) s where s.sum_prv_qty < s.ord_qty ) select f.loc, f.item, f.purch, f.pick_qty, f.from_qty f_from_qty, f.to_qty f_to_qty , o.ordno, o.qty, o.from_qty o_from_qty, o.to_qty o_to_qty , least( f.loc_qty , least(o.to_qty, f.to_qty) - greatest(o.from_qty, f.from_qty) + 1 ) pick_ord_qty from fifo f join orderlines o on o.item = f.item and o.to_qty >= f.from_qty and o.from_qty <= f.to_qty order by f.item, f.purch, o.ordno;We've now developed the multi-order batch-picking FIFO query with all the columns showing the intermediate calculations, so now we clean up the query to contain only the needed columns for the picking list in order of location.
with orderlines as ( select o.ordno, o.item, o.qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and 1 preceding ),0) + 1 from_qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and current row ),0) to_qty from orderline o where ordno in (51, 62, 73) ), orderbatch as ( select o.item, sum(o.qty) qty from orderlines o group by o.item ), fifo as ( select s.loc, s.item, s.loc_qty , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty , sum_prv_qty + 1 from_qty , least(sum_qty, ord_qty) to_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ),0) sum_qty from orderbatch o join inventory i on i.item = o.item ) s where s.sum_prv_qty < s.ord_qty ) select f.loc, f.item, f.pick_qty pick_at_loc, o.ordno , least( f.loc_qty , least(o.to_qty, f.to_qty) - greatest(o.from_qty, f.from_qty) + 1 ) qty_for_ord from fifo f join orderlines o on o.item = f.item and o.to_qty >= f.from_qty and o.from_qty <= f.to_qty order by f.loc, o.ordno;And as a last addition to make our forklift operator really efficient, we can add on the odd/even-numbered aisle ordering to this query too, ending up with this ultimate query.
with orderlines as ( select o.ordno, o.item, o.qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and 1 preceding ),0) + 1 from_qty , nvl(sum(o.qty) over ( partition by o.item order by o.ordno rows between unbounded preceding and current row ),0) to_qty from orderline o where ordno in (51, 62, 73) ), orderbatch as ( select o.item, sum(o.qty) qty from orderlines o group by o.item ), fifo as ( select s.loc, s.item, s.loc_qty , least(s.loc_qty, s.ord_qty - s.sum_prv_qty) pick_qty , sum_prv_qty + 1 from_qty , least(sum_qty, ord_qty) to_qty from ( select o.item, o.qty ord_qty, i.loc, i.qty loc_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and 1 preceding ),0) sum_prv_qty , nvl(sum(i.qty) over ( partition by i.item order by i.purch, i.loc rows between unbounded preceding and current row ),0) sum_qty from orderbatch o join inventory i on i.item = o.item ) s where s.sum_prv_qty < s.ord_qty ), pick as ( select to_number(substr(f.loc,1,1)) warehouse , substr(f.loc,3,1) aisle , dense_rank() over ( order by to_number(substr(f.loc,1,1)), -- warehouse substr(f.loc,3,1) -- aisle ) aisle_no , to_number(substr(f.loc,5,2)) position , f.loc, f.item, f.pick_qty pick_at_loc, o.ordno , least( f.loc_qty , least(o.to_qty, f.to_qty) - greatest(o.from_qty, f.from_qty) + 1 ) qty_for_ord from fifo f join orderlines o on o.item = f.item and o.to_qty >= f.from_qty and o.from_qty <= f.to_qty ) select p.loc, p.item, p.pick_at_loc, p.ordno, p.qty_for_ord from pick p order by p.warehouse , p.aisle_no , case when mod(p.aisle_no,2) = 1 then p.position else -p.position end;Over these two modules you now have seen the process of developing a real-life use case for analytic functions step by step by adding a little more analytic functions one at a time viewing the intermediate results and gradually letting the query grow more complex as you go along. Often this can be a typical way of developing analytic queries.
Forecasting
The basis of this module is a table of monthly sales data for three years for two items, snowchain and sunshade. The snowchain sells well in the winter and hardly anything in the summer with a trend of selling more and more each year. While the the sunshade sells well in the summer with a downward trend less and less each year.
select * from monthly_sales order by item, mth;
We will be forecasting with a time series model using seasonal adjustment and exponential smoothing very similar to the model explained here: http://people.duke.edu/~rnau/411outbd.htm (link given for your perusal later, not necessary to read now to complete the hands-on-lab.)
First we build a 48 month time series for each item, using an inline view to create 48 months (the 3 years we have sales data for + the 1 year we will be forecasting.) With a partitioned outer join to the sales data, this creates a row source with exactly 48 rows per item numbered 1 to 48 in the TS (Time Serie) column.select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth order by ms.item, mths.mth;We take the previous query and put it in a WITH subquery factoring clause. This will be the method used for the rest of this module - build one step at a time and then tack it onto the chain of WITH clauses for building the next step.
In this step we wish to calculate a socalled centered moving average (CMA). For each month we use analytic AVG to create a moving average with a window one year in length, first we use a window of -5 to +6 months, and then a window of -6 to +5 months. By taking the average of those 2 (add them and divide by 2) we get the centered moving average. But it only makes sense to calculate that CMA for those months where we actually have a years worth of data "surrounding" the month, hence we only calculate it for months 7 through 30.
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ) select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 order by item, ts;We put the CMA calculation in a second WITH clause and continue with calculating the seasonality of each month. It is a factor that shows how much that particular month is selling compared to the average month and we calculate it by taking the quantity of the month and divide by the CMA. (The model will fail further on if this becomes zero, so we change all zero quantities to a very small quantity instead - that allows the model to work.)
So we've calculated a seasonality for each individual month by the simple division. But there might be small differences in seasonality throughout the years (some winters might be more snow than others), so for a better result we want a seasonality factor that is the average per month, which we achieve by PARTION BY ITEM, MTHNO (where mthno is 1..12). This means that we get an average seasonality for january, an average for february and so on. Because of the way the analytic function with PARTITION clause works, this means that the average january seasonality value is repeated for all the 4 januaries per item - also those in the year we are trying to forecast!
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ), s2 as ( select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 ) select s2.* , nvl(avg( case qty when 0 then 0.0001 else qty end / nullif(cma,0) ) over ( partition by item, mthno ),0) s -- seasonality from s2 order by item, ts;Having calculated the seasonality, for the 3 years we have sales data we divide the sales with the seasonality factor and thereby get a deseasonalized quantity. The deseasonalization "smoothes" the graph of the sales into something approaching a straight line, as we'll see in the next step.
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ), s2 as ( select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 ), s3 as ( select s2.* , nvl(avg( case qty when 0 then 0.0001 else qty end / nullif(cma,0) ) over ( partition by item, mthno ),0) s -- seasonality from s2 ) select s3.* , case when ts <= 36 then nvl(case qty when 0 then 0.0001 else qty end / nullif(s,0), 0) end des -- deseasonalized from s3 order by item, ts;Time to use some more analytic functions. The deseasonalized quantity approaches a straight line - with functions REGR_INTERCEPT and REGR_SLOPE we can do a linear regression and get the defining parameters of the straight line that is the best fit to our deseasonalized sales. With the parameters (des,ts) we perform linear regression on a graph with des on the Y axis and ts on the X axis.
REGR_INTERCEPT gives us the point where the line intercepts the Y axis (meaning the Y value for X=0), and REGR_SLOPE gives us the slope (meaning how much Y goes either up or down when X increases by 1.) Since our X axis is the month number 1 to 48, we can get the Y value of the straight line (the trend line) by taking the intercept point and adding the month number multiplied by the slope.
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ), s2 as ( select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 ), s3 as ( select s2.* , nvl(avg( case qty when 0 then 0.0001 else qty end / nullif(cma,0) ) over ( partition by item, mthno ),0) s -- seasonality from s2 ), s4 as ( select s3.* , case when ts <= 36 then nvl(case qty when 0 then 0.0001 else qty end / nullif(s,0), 0) end des -- deseasonalized from s3 ) select s4.* , regr_intercept(des,ts) over (partition by item) + ts*regr_slope(des,ts) over (partition by item) t -- trend from s4 order by item, ts;Viewed on a graph I can get a feeling about how perfect the seasonal variations for the item is. The closer the deseasonalized graph is to a straight line, the closer the item is to having the exact same seasonal pattern every year. For snowchain here we can see some "hick-ups" which are due to months with very low or no sales, but the hick-ups even out and the general trend follows the trend line nicely.

So the straight trend line in the graph extends out into the year we want to forecast. This straight line in essence is the forecast of deseasonalized sales, so to get the forecast we want, we simply have to reseasonalize it again by multiplying with the seasonality factor. This is easy, since we saw above that the seasonality factor is available in all the months, also the ones for the forecast year - we simply have to multiply the trend line with the seasonality, and the result is our forecast.
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ), s2 as ( select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 ), s3 as ( select s2.* , nvl(avg( case qty when 0 then 0.0001 else qty end / nullif(cma,0) ) over ( partition by item, mthno ),0) s -- seasonality from s2 ), s4 as ( select s3.* , case when ts <= 36 then nvl(case qty when 0 then 0.0001 else qty end / nullif(s,0), 0) end des -- deseasonalized from s3 ), s5 as ( select s4.* , regr_intercept(des,ts) over (partition by item) + ts*regr_slope(des,ts) over (partition by item) t -- trend from s4 ) select s5.* , t * s forecast --reseasonalized from s5 order by item, ts;Checking the graphs we can see whether the reseasonalized sales match the actual sales fairly well for the three years we have sales data. If they match well, then our model is fairly good and the reseasonalized sales for the forecast year is probably a fairly good forecast. We can also see that the forecast for both items keep the "shape" of the graph for the previous years, but the shape just is a bit bigger for snowchain (upward trend) and a bit smaller for sunshade (downward trend.)


The previous query showed all the columns of the calculations along the way. Now let us just keep the columns of interest, and then we can use analytic SUM function partitioned by YR on both the actual quantity sold as well as the reseasonalized (forecast) quantity. This gives us a "quick-and-dirty" way to get a feel for how well the model matches the reality.
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ), s2 as ( select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 ), s3 as ( select s2.* , nvl(avg( case qty when 0 then 0.0001 else qty end / nullif(cma,0) ) over ( partition by item, mthno ),0) s -- seasonality from s2 ), s4 as ( select s3.* , case when ts <= 36 then nvl(case qty when 0 then 0.0001 else qty end / nullif(s,0), 0) end des -- deseasonalized from s3 ), s5 as ( select s4.* , regr_intercept(des,ts) over (partition by item) + ts*regr_slope(des,ts) over (partition by item) t -- trend from s4 ) select item, mth, qty , t * s forecast --reseasonalized , sum(qty) over (partition by item, yr) qty_yr , sum(t * s) over (partition by item, yr) fc_yr from s5 order by item, ts;Having satisfied ourselves that the model matches reality "good enough", we can present the data simplified for the end users, so they just get the information about actual sales and forecast sales that they are interested in. Using analytic SUM to give them a yearly sum also helps the users to get a feel for the data.
with s1 as ( select ms.item, mths.ts, mths.mth, ms.qty , extract(year from mths.mth) yr , extract(month from mths.mth) mthno from ( select add_months(date '2011-01-01', level-1) mth, level ts --time serie from dual connect by level <= 48 ) mths left outer join monthly_sales ms partition by (ms.item) on ms.mth = mths.mth ), s2 as ( select s1.* , case when ts between 7 and 30 then (nvl(avg(qty) over ( partition by item order by ts rows between 5 preceding and 6 following ),0) + nvl(avg(qty) over ( partition by item order by ts rows between 6 preceding and 5 following ),0)) / 2 else null end cma -- centered moving average from s1 ), s3 as ( select s2.* , nvl(avg( case qty when 0 then 0.0001 else qty end / nullif(cma,0) ) over ( partition by item, mthno ),0) s -- seasonality from s2 ), s4 as ( select s3.* , case when ts <= 36 then nvl(case qty when 0 then 0.0001 else qty end / nullif(s,0), 0) end des -- deseasonalized from s3 ), s5 as ( select s4.* , regr_intercept(des,ts) over (partition by item) + ts*regr_slope(des,ts) over (partition by item) t -- trend from s4 ) select item , mth , case when ts <= 36 then qty else round(t * s) end qty , case when ts <= 36 then 'Actual' else 'Forecast' end type , sum( case when ts <= 36 then qty else round(t * s) end ) over ( partition by item, yr ) qty_yr from s5 order by item, ts;And that final query can then be represented in an easily readable graph.
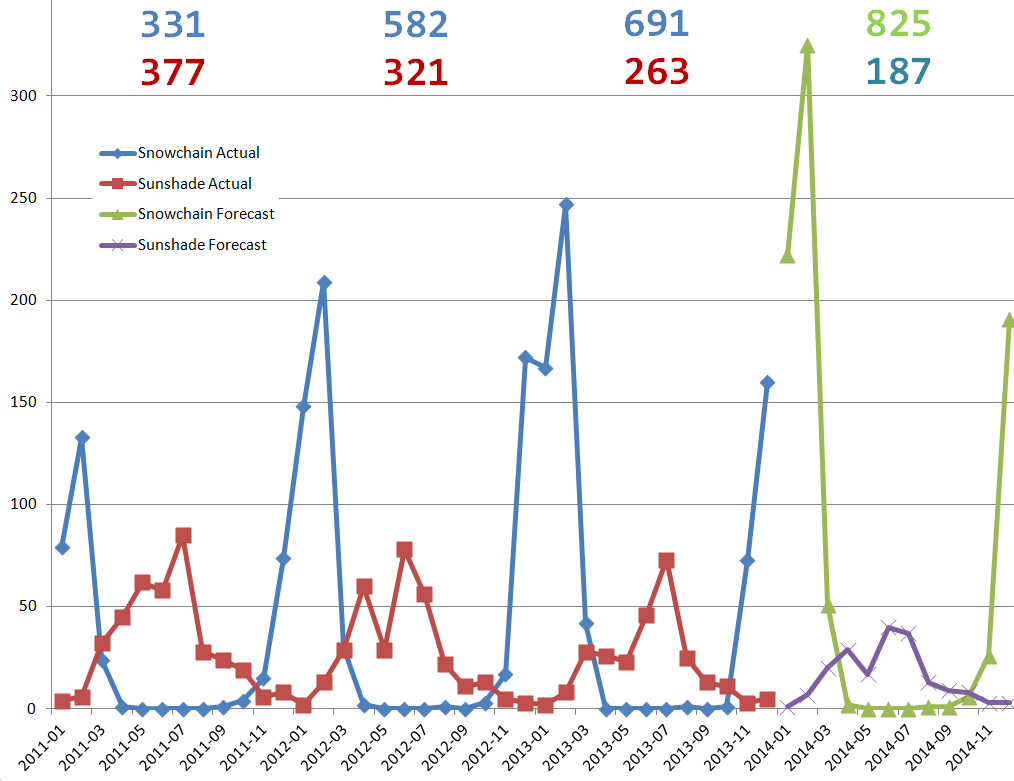
You have in this final module seen a complex calculation broken down into small individually simpler calculations with a series of WITH clauses. Doing analytic statement development step for step helps a lot in modularization of a large statement, so each part becomes relatively simple to calculate. Even the more advanced analytic functions like the linear regression functions are not so difficult when used as a single simple step in the more complex whole. That way it becomes easier to keep track of what's happening in each step.
In the 6 modules of this Hands-On-Lab, methods of using analytic functions have been covered - from the simple to the more complex. Many analytic functions exist that have not been covered, but once you master the three analytic clauses (partition, order and windowing clauses) and get used to the way of thinking (that data from other rows - few or many - can be part of calculations on this row), you will start to use analytic functions more in your daily life as a developer. Just start using them - the more you do, the more you'll recognize more and more opportunities for using them in your code, thus making your applications more efficient and faster and your users (and boss) happier.