HOL Row Pattern Matching
- Tutorial HOL Row Pattern Matching
- Description Hands-On-Lab for ODTUG Kscope. The modules give examples of row pattern matching (MATCH_RECOGNIZE) queries, starting with a coverage of the basics using stock ticker examples in module 1, then in the following modules giving a varied set of use cases for row pattern matching. If you know the basics, you can skip module 1 and pick what you find interesting of the other modules.
- Area SQL General / SQL Query
- Contributor Kim Berg Hansen
- Created Sunday June 11, 2017
- Modules 7
Prerequisite SQL
/* Module 1 */ create table ticker ( symbol varchar2(10) , day date , price number ); insert into ticker values('PLCH', DATE '2011-04-01', 12); insert into ticker values('PLCH', DATE '2011-04-02', 17); insert into ticker values('PLCH', DATE '2011-04-03', 19); insert into ticker values('PLCH', DATE '2011-04-04', 21); insert into ticker values('PLCH', DATE '2011-04-05', 25); insert into ticker values('PLCH', DATE '2011-04-06', 12); insert into ticker values('PLCH', DATE '2011-04-07', 15); insert into ticker values('PLCH', DATE '2011-04-08', 20); insert into ticker values('PLCH', DATE '2011-04-09', 24); insert into ticker values('PLCH', DATE '2011-04-10', 25); insert into ticker values('PLCH', DATE '2011-04-11', 19); insert into ticker values('PLCH', DATE '2011-04-12', 15); insert into ticker values('PLCH', DATE '2011-04-13', 25); insert into ticker values('PLCH', DATE '2011-04-14', 25); insert into ticker values('PLCH', DATE '2011-04-15', 14); insert into ticker values('PLCH', DATE '2011-04-16', 12); insert into ticker values('PLCH', DATE '2011-04-17', 14); insert into ticker values('PLCH', DATE '2011-04-18', 24); insert into ticker values('PLCH', DATE '2011-04-19', 23); insert into ticker values('PLCH', DATE '2011-04-20', 22); commit; /* Module 2 */ create table numbers (numval) as select 1 from dual union all select 2 from dual union all select 3 from dual union all select 5 from dual union all select 6 from dual union all select 7 from dual union all select 10 from dual union all select 11 from dual union all select 12 from dual union all select 20 from dual; commit; /* Module 3 */ create table emp_hire_periods ( emp_id integer not null , name varchar2(20 char) not null , start_date date not null , end_date date , title varchar2(20 char) not null , constraint emp_hire_periods_pk primary key (emp_id, start_date) , period for employed_in (start_date, end_date) ); insert into emp_hire_periods values (142, 'Harold King' , date '2010-07-01', date '2012-04-01', 'Product Director' ); insert into emp_hire_periods values (142, 'Harold King' , date '2012-04-01', null , 'Managing Director'); insert into emp_hire_periods values (143, 'Mogens Juel' , date '2010-07-01', date '2014-01-01', 'IT Technician' ); insert into emp_hire_periods values (143, 'Mogens Juel' , date '2014-01-01', date '2016-06-01', 'Sys Admin' ); insert into emp_hire_periods values (143, 'Mogens Juel' , date '2014-04-01', date '2015-10-01', 'Code Tester' ); insert into emp_hire_periods values (143, 'Mogens Juel' , date '2016-06-01', null , 'IT Manager' ); insert into emp_hire_periods values (144, 'Axel de Proef', date '2010-07-01', date '2013-07-01', 'Sales Manager' ); insert into emp_hire_periods values (144, 'Axel de Proef', date '2012-04-01', null , 'Product Director' ); insert into emp_hire_periods values (145, 'Zoe Thorston' , date '2014-02-01', null , 'IT Developer' ); insert into emp_hire_periods values (145, 'Zoe Thorston' , date '2019-02-01', null , 'Scrum Master' ); insert into emp_hire_periods values (146, 'Lim Tok Lo' , date '2014-10-01', date '2016-02-01', 'Forklift Operator'); insert into emp_hire_periods values (146, 'Lim Tok Lo' , date '2017-03-01', null , 'Warehouse Manager'); insert into emp_hire_periods values (147, 'Ursula Mwbesi', date '2014-10-01', date '2015-05-01', 'Delivery Manager' ); insert into emp_hire_periods values (147, 'Ursula Mwbesi', date '2016-05-01', date '2017-03-01', 'Warehouse Manager'); insert into emp_hire_periods values (147, 'Ursula Mwbesi', date '2016-11-01', null , 'Operations Chief' ); commit; /* Module 4 */ create table space ( tabspace varchar2(30) , sampledate date , gigabytes number ); insert into space values ('MYSPACE' , date '2014-02-01', 100); insert into space values ('MYSPACE' , date '2014-02-02', 103); insert into space values ('MYSPACE' , date '2014-02-03', 116); insert into space values ('MYSPACE' , date '2014-02-04', 129); insert into space values ('MYSPACE' , date '2014-02-05', 142); insert into space values ('MYSPACE' , date '2014-02-06', 160); insert into space values ('MYSPACE' , date '2014-02-07', 165); insert into space values ('MYSPACE' , date '2014-02-08', 210); insert into space values ('MYSPACE' , date '2014-02-09', 230); insert into space values ('MYSPACE' , date '2014-02-10', 239); insert into space values ('YOURSPACE', date '2014-02-06', 50); insert into space values ('YOURSPACE', date '2014-02-07', 53); insert into space values ('YOURSPACE', date '2014-02-08', 72); insert into space values ('YOURSPACE', date '2014-02-09', 97); insert into space values ('YOURSPACE', date '2014-02-10', 101); insert into space values ('HISSPACE', date '2014-02-06', 100); insert into space values ('HISSPACE', date '2014-02-07', 130); insert into space values ('HISSPACE', date '2014-02-08', 145); insert into space values ('HISSPACE', date '2014-02-09', 200); insert into space values ('HISSPACE', date '2014-02-10', 225); insert into space values ('HISSPACE', date '2014-02-11', 255); insert into space values ('HISSPACE', date '2014-02-12', 285); insert into space values ('HISSPACE', date '2014-02-13', 315); commit; /* Module 5 */ create table dept( deptno number(2) constraint pk_dept primary key , dname varchar2(14) , loc varchar2(13) ); create table emp( empno number(4) constraint pk_emp primary key , ename varchar2(10) , job varchar2(9) , mgr number(4) , hiredate date , sal number(7,2) , comm number(7,2) , deptno number(2) constraint fk_deptno references dept ); insert into dept values (10,'ACCOUNTING','NEW YORK'); insert into dept values (20,'RESEARCH','DALLAS'); insert into dept values (30,'SALES','CHICAGO'); insert into dept values (40,'OPERATIONS','BOSTON'); insert into emp values (7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,null,20); insert into emp values (7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30); insert into emp values (7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30); insert into emp values (7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,null,20); insert into emp values (7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30); insert into emp values (7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,null,30); insert into emp values (7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,null,10); insert into emp values (7788,'SCOTT','ANALYST',7566,to_date('19-04-1987','dd-mm-yyyy'),3000,null,20); insert into emp values (7839,'KING','PRESIDENT',null,to_date('17-11-1981','dd-mm-yyyy'),5000,null,10); insert into emp values (7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30); insert into emp values (7876,'ADAMS','CLERK',7788,to_date('23-05-1987', 'dd-mm-yyyy'),1100,null,20); insert into emp values (7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,null,30); insert into emp values (7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,null,20); insert into emp values (7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,null,10); commit; /* Module 6 */ create table sites (study_site number, cnt number); insert into sites (study_site,cnt) values (1001,3407); insert into sites (study_site,cnt) values (1002,4323); insert into sites (study_site,cnt) values (1004,1623); insert into sites (study_site,cnt) values (1008,1991); insert into sites (study_site,cnt) values (1011,885); insert into sites (study_site,cnt) values (1012,11597); insert into sites (study_site,cnt) values (1014,1989); insert into sites (study_site,cnt) values (1015,5282); insert into sites (study_site,cnt) values (1017,2841); insert into sites (study_site,cnt) values (1018,5183); insert into sites (study_site,cnt) values (1020,6176); insert into sites (study_site,cnt) values (1022,2784); insert into sites (study_site,cnt) values (1023,25865); insert into sites (study_site,cnt) values (1024,3734); insert into sites (study_site,cnt) values (1026,137); insert into sites (study_site,cnt) values (1028,6005); insert into sites (study_site,cnt) values (1029,76); insert into sites (study_site,cnt) values (1031,4599); insert into sites (study_site,cnt) values (1032,1989); insert into sites (study_site,cnt) values (1034,3427); insert into sites (study_site,cnt) values (1036,879); insert into sites (study_site,cnt) values (1038,6485); insert into sites (study_site,cnt) values (1039,3); insert into sites (study_site,cnt) values (1040,1105); insert into sites (study_site,cnt) values (1041,6460); insert into sites (study_site,cnt) values (1042,968); insert into sites (study_site,cnt) values (1044,471); insert into sites (study_site,cnt) values (1045,3360); commit; /* Module 7 */ create table items as select to_char(to_date(level,'J'),'Jsp') item_name , level item_value from dual connect by level <= 10; /* === */ alter session set nls_date_format = 'YYYY-MM-DD';
Stock Ticker (The Basics)
The basis of this module is a ticker table storing stock prices per day, in this case for the imaginary stock PLCH (PL/SQL Challenge).
select * from ticker order by symbol, day;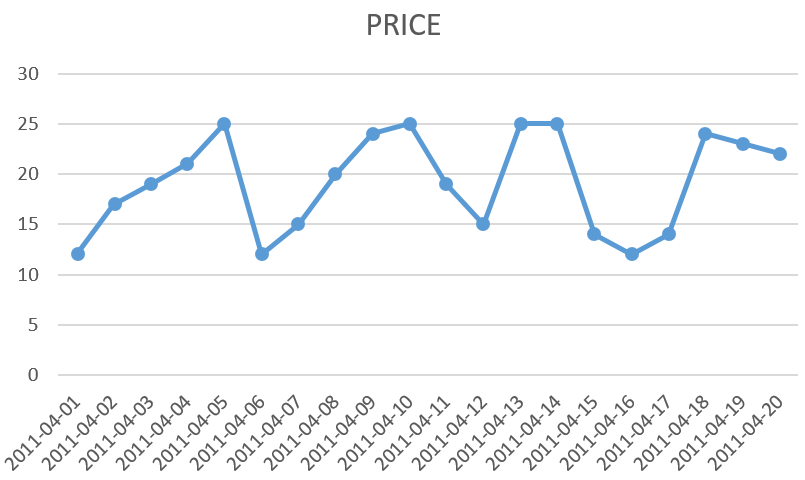
A classic example of row pattern matching is to search to V shapes in the graph. Here is an example of that taken from the Data Warehousing Guide manual. Just try to execute it, then afterwards we'll go through the parts of it.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , final last(down.day) as bottom_day , final last(up.day) as end_day , match_number() as match_num , classifier() as var_match all rows per match after match skip to last up pattern ( strt down+ up+ ) define down as down.price < prev(down.price) , up as up.price > prev(up.price) ) order by symbol, match_num, day;So we'll try different statements each showing parts of the statement above until we end with the same statement.
At first in the next statement we'll try to search for the "down" part of the V shape first, using the different parts of the MATCH_RECOGNIZE clause:
- PARTITION BY works like in analytic functions, it splits the data into partitions where the pattern matching is executed independently in each partition. Here we do it for each ticker symbol (our data only has one symbol, but this way the statement works even with multiple symbols.)
- ORDER BY is a cornerstone in pattern matching, you cannot recognize a pattern in the data if they are not ordered.
- DEFINE is a method of classifying the rows depending on conditions. If the condition right side of AS is true, the row will be classified with the classifier variable name left side of AS. There can be multiple classification conditions, which will be tested one by one in order, until the row satisfies one of the conditions. In the conditions can be used various navigational functions like PREV, NEXT, FIRST, LAST that return values from other rows. Using PREV here we test for whether a row has a price less than the price of the previous row - if yes, then the row is classified as a DOWN row.
- Having classified the rows using DEFINE, we can then use the classification names we have defined in the PATTERN clause to state what sequence of row classifications we are looking for. Here we will look for STRT DOWN+, which is a syntax similar to regular expressions, in that we state we look for exactly 1 row classified STRT followed by 1 or more rows classified DOWN. But we have not created a STRT classification definition in the DEFINE clause? We could have done it with something like "strt as 1=1", but that is not necessary, because an "undefined" classifier simply becomes the default classifier that a row gets if it does not satisfy any of the classifications of the DEFINE clause.
- When the next row no longer fullfills the pattern, the match is completed and the pattern searching can start over to try and find if there are more matches of the pattern. With the AFTER MATCH clause we tell it where to start the next search for a match. In this case we use the default SKIP PAST LAST ROW, which will start the next search beginning at the row following the final DOWN row of the previous match.
- Each match we find, we can choose between either getting all the rows or just a single aggregate row. Here we choose ALL ROWS PER MATCH.
- And finally we specify what output we want in the MEASURES clause, which can contain row column values, aggregates, navigation functions, or special functions like MATCH_NUMBER() and CLASSIFIER(). With a SELECT * we get first the columns in PARTITION BY and ORDER BY, then the columns of the MEASURES, and finally the "rest" of the table columns (those not used in PARTITION or ORDER BY.)
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , running last(down.day) as down_day , final last(down.day) as bottom_day , match_number() as match_num , classifier() as var_match all rows per match after match skip past last row pattern ( strt down+ ) define down as down.price < prev(down.price) ) order by symbol, match_num, day;We can do the exact same thing defining UP to search for "up" parts of the V shape. Just like in the statement above, we can observe the difference between RUNNING and FINAL keyword in front of the navigational functions - in this case LAST. RUNNING (which is the default if nothing is specified) evaluates on the row itself, while FINAL evaluates on the last row of the match.
MATCH_NUMBER and CLASSIFIER are very useful to add to your query while you are developing it and testing out your pattern. When you go to production it may often not be necessary to include these functions, but they are very instructive to observe how the pattern matching works.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , running last(up.day) as up_day , final last(up.day) as top_day , match_number() as match_num , classifier() as var_match all rows per match after match skip past last row pattern ( strt up+ ) define up as up.price > prev(up.price) ) order by symbol, match_num, day;Just like we can use RUNNING and FINAL on the navigational functions (used on LAST in the previous statement), we can also use them on aggregate/analytic functions. Here we use a RUNNING and FINAL COUNT, where RUNNING works like analytic ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW and FINAL works like ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
select * from ticker match_recognize ( partition by symbol order by day measures final count(up.*) as days_up , up.price - prev(up.price) as up_day , (up.price - strt.price) / running count(up.*) as running_up_avg , (final last(up.price) - strt.price) / final count(up.*) as total_up_avg , up.price - strt.price as up_total , match_number() as match_num , classifier() as var_match all rows per match after match skip to last up pattern ( strt up+ ) define up as up.price > prev(up.price) ) order by symbol, match_num, day;So we can combine the search for downs and the search for ups in a single statement, where we have two DEFINE classifications and use both in the PATTERN clause, so we specify we want any one row, followed by at least one DOWN row, followed by at least one UP row - thereby finding V shapes in the graph.
We use the FINAL LAST twice, since by specifying down.day respectively up.day, we get the last DAY value of those rows classified DOWN respectively UP. If we had only used last(day) without specifying any classification variably in front, we would get the DAY value of the last row in the match, whichever classification that row might have. In this case the last row of the match will always be an UP row, but that is not always the case. You can try running this query as is and then edit and change last(down.day) to last(day) and see what happens.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , final last(down.day) as bottom_day , final last(up.day) as end_day , match_number() as match_num , classifier() as var_match all rows per match after match skip past last row pattern ( strt down+ up+ ) define down as down.price < prev(down.price) , up as up.price > prev(up.price) ) order by symbol, match_num, day;But the above query is not quite identical to the example from the manual given at the top of the module, and it does also not quite give the same result. The query from the manual does not use AFTER MATCH SKIP PAST LAST ROW, it uses AFTER MATCH SKIP TO LAST UP. The difference is that when a match has been found, it will begin searching for a new match from the last row of the old match, not the row that follows the last row. For our V shape search, this is important, as after the last UP row can very easily be a DOWN row.
So here we'll repeat the manual query with the change to SKIP TO LAST UP, so you can observe the difference between the output of the previous query and this one, where you'll notice two rows with 2011-04-10, one as last UP row in MATCH_NUM 1, then again as STRT row in MATCH_NUM 2. And this is perfectly OK that a row can become part of more than one match, and hence be output more than once.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , final last(down.day) as bottom_day , final last(up.day) as end_day , match_number() as match_num , classifier() as var_match all rows per match after match skip to last up -- Changed here pattern ( strt down+ up+ ) define down as down.price < prev(down.price) , up as up.price > prev(up.price) ) order by symbol, match_num, day;All the examples so far have used ALL ROWS PER MATCH. But we can also specify ONE ROW PER MATCH, which in effect is somewhat like changing from using analytic functions (ALL ROWS PER MATCH) to aggregating with GROUP BY (ONE ROW PER MATCH.) So we can get an aggregated row for each match like this.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , strt.price as start_price , final last(down.day) as bottom_day , final last(down.price) as bottom_price , final last(up.day) as end_day , final last(up.price) as end_price , match_number() as match_num one row per match after match skip to last up pattern ( strt down+ up+ ) define down as down.price < prev(down.price) , up as up.price > prev(up.price) ) order by symbol, match_num;The use of FINAL can be nice as sort of "self-documenting", but when we use ONE ROW PER MATCH it does not matter that much, as RUNNING in effect gives us the same result. Date in measures are evaluated on the last row when we use ONE ROW PER MATCH, so using RUNNING will be evaluated on the last row and hence give the same result as FINAL.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , strt.price as start_price , running last(down.day) as bottom_day , running last(down.price) as bottom_price , running last(up.day) as end_day , running last(up.price) as end_price , match_number() as match_num one row per match after match skip to last up pattern ( strt down+ up+ ) define down as down.price < prev(down.price) , up as up.price > prev(up.price) ) order by symbol, match_num;But in these examples we can even simplify it further when we use ONE ROW PER MATCH, since when it evaluates on the last row, we don't even need to use LAST navigational function. We can get the same result by simply using the classification variables.
select * from ticker match_recognize ( partition by symbol order by day measures strt.day as start_day , strt.price as start_price , down.day as bottom_day , down.price as bottom_price , up.day as end_day , up.price as end_price , match_number() as match_num one row per match after match skip to last up pattern ( strt down+ up+ ) define down as down.price < prev(down.price) , up as up.price > prev(up.price) ) order by symbol, match_num;However, using FINAL LAST can be nice as self-documenting code, plus it has the advantage of making it quicker to switch between ONE ROW PER MATCH and ALL ROWS PER MATCH, which often is needed as a debugging device for finding out if you have problems with your pattern definitions.
You have now seen the basic elements of the MATCH_RECOGNIZE clause, exemplified with stock ticker data. The next modules will give various use-cases, some where the thinking of "patterns" make sense, some where it is more obscure how it is a "pattern" but where the MATCH_RECOGNIZE clause is a very efficient solution.
Grouping Sequences
The basis of this module is a simple table of integers.
select * from numbers order by numval;Our task is to group all consecutive numbers (sequences). Whenever there is a gap, a new group should be started.
To start with, in the MATCH_RECOGNIZE we order by NUMVAL, so we can define a row classifier B with a condition that the value should be precisely 1 larger than the previous value.
The pattern A B* then states, that we start with any row, then must come zero or more occurences of a row classified as B. So the first row will be A, then the match will go on matching B rows until we reach a "gap" where the row no longer will be classified B. At that point the match ends, and the following row (which will be the first in the new group) will be an A row and starts a new match. We can observe the behaviour with ALL ROWS PER MATCH.
select * from numbers match_recognize ( order by numval measures match_number() match_no , classifier() class , a.numval a_numval , b.numval b_numval , first(numval) firstval , final last(numval) lastval , final count(*) cnt all rows per match pattern ( a b* ) define b as numval = prev(numval) + 1 ) order by numval;Having tested the behaviour with ALL ROWS PER MATCH, it is simple to change to ONE ROW PER MATCH (which is default so we can simply omit the PER MATCH specification) to get the desired groups of sequences.
select * from numbers match_recognize ( order by numval measures first(numval) firstval , last(numval) lastval , count(*) cnt pattern ( a b* ) define b as numval = prev(numval) + 1 ) order by firstval;The method can easily be adapted to for example find groups of consecutive dates. Also the condition could be more complex than simply "value must be exactly one higher than the previous".
For example we can say that we can accept a gap of one integer missing from the sequence and still allow it to be a group by a simple change to the DEFINE clause. Or you can try it out with "+ 3" and see what happens.
select * from numbers match_recognize ( order by numval measures first(numval) firstval , last(numval) lastval , count(*) cnt pattern ( a b* ) define b as numval <= prev(numval) + 2 -- Just change here ) order by firstval;This module has shown a basic, but useful, pattern matching technique to group rows as long as some condition is met. A pattern of A B* and a definition of B with some condition (simple or complex) using PREV to compare the row to the previous row, that is a "template" that can be applied to several use cases.
Merge DATE ranges
The basis of this module is a table defining employee hire periods with a START_DATE and an END_DATE and TITLE of the job they had in that period. Sometimes they have more than one job in a period. NULL as END_DATE indicates the period is still on-going and currently valid.
select emp_id , name , start_date , end_date , title from emp_hire_periods order by emp_id, start_date;The table is defined using temporal validity with the PERIOD FOR clause. You can see the DDL here (no need to execute it, the setup code has done that):
create table emp_hire_periods ( emp_id integer not null , name varchar2(20 char) not null , start_date date not null , end_date date , title varchar2(20 char) not null , constraint emp_hire_periods_pk primary key (emp_id, start_date) , period for employed_in (start_date, end_date) );
When using temporal validity, the valid period of the row goes from and including START_DATE, but to and excluding END_DATE. This is called a half-open interval (as opposed to closed or open intervals) and is very practical to use for date ranges.
As a side note, having temporal validity enabled on the table allows us to use AS OF PERIOD FOR in a query to view hire periods data as of a specific date. For example there were not so many employees in 2010:
select emp_id , name , start_date , end_date , title from emp_hire_periods as of period for employed_in date '2010-07-01' order by emp_id, start_date;In 2016 there were more employees and some of the existing had new job titles:
select emp_id , name , start_date , end_date , title from emp_hire_periods as of period for employed_in date '2016-07-01' order by emp_id, start_date;What we want to output is a list where we have merged adjoining or overlapping date ranges, so that we can see for example that Mogens Juel has been employed from 2010-07-01 until current time (NULL as END_DATE) and in that period has had 4 jobs.
First we can attempt to do similar to how we found consecutive numbers. We can define ADJOIN_OR_OVERLAP as rows where the START_DATE is smaller than or equal to the END_DATE of the previous row, where we order the rows by START_DATE, END_DATE. And then we look for a pattern of any row followed by zero or more adjoining or overlapping rows.
select emp_id , name , start_date , end_date , jobs from emp_hire_periods match_recognize ( partition by emp_id order by start_date, end_date measures max(name) as name , first(start_date) as start_date , last(end_date) as end_date , count(*) as jobs pattern ( strt adjoin_or_overlap* ) define adjoin_or_overlap as start_date <= prev(end_date) ) order by emp_id, start_date;It does merge some of the date ranges when you check the output, but not all. For example Mogens Juel is not completely merged, there should have been a single row only for him with 4 jobs. The problem is that when we order his rows by start_date, the "Code Tester" and "IT Manager" rows are compared and not found overlapping. A comparison like this to the previous row fails to discover that both rows are adjoining or overlapping to "Sys Admin".
Would it help to order by END_DATE first instead of START_DATE? Let's try it:
select emp_id , name , start_date , end_date , jobs from emp_hire_periods match_recognize ( partition by emp_id order by end_date, start_date measures max(name) as name , first(start_date) as start_date , last(end_date) as end_date , count(*) as jobs pattern ( strt adjoin_or_overlap* ) define adjoin_or_overlap as start_date <= prev(end_date) ) order by emp_id, start_date;The output has changed, but Mogens Juel still wrongly is shown twice. With the changed ordering, the first attempt at finding a match for Mogens Juel will try to compare the "IT Technician" row with the "Code Tester" row and fail to find an overlap.
No matter which ordering we choose, we cannot get all the overlaps in a single match by simply comparing a row to the previous row. We need a different way to handle this.
Take a closer look at the rows of Mogens Juel:
select emp_id , name , start_date , end_date , title from emp_hire_periods where emp_id = 143 order by emp_id, start_date;A better approach will be to compare the START_DATE of a row with the highest END_DATE that we have found so far in the match.
We could attempt to do this with a definition that says START_DATE <= MAX(END_DATE), but this will not work. MAX(END_DATE) would not be the highest END_DATE of all the previous rows, it would be the highest of all the previous rows plus the current row. If this had been analytic functions, we would have liked a window of ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING, but we are getting ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. But we cannot specify windows like that in our definition.
Also if we try such a definition, we will at minimum get an error and possibly crash our session. Depending on client and DB version, we might get "ORA-03113: end-of-file on communication channel" or "java.lang.NullPointerException". Here on LiveSQL you will get a generic "Error" after hanging some time and your session will be unusable afterwards - you will need to close your browser and start over logging in again in a new session.
So do not call this statement, it just illustrates a point:
/* select emp_id , name , start_date , end_date , jobs from emp_hire_periods match_recognize ( partition by emp_id order by start_date, end_date measures max(name) as name , first(start_date) as start_date , max(end_date) as end_date , count(*) as jobs pattern ( strt adjoin_or_overlap* ) define adjoin_or_overlap as start_date <= max(end_date) ) order by emp_id, start_date; */Instead we need to reverse the logic. Rather than trying to compare this row to the max of all previous rows (which can't work), we compare the max of all previous rows + current row with the value of the next row:
select emp_id , name , start_date , end_date , jobs from emp_hire_periods match_recognize ( partition by emp_id order by start_date, end_date measures max(name) as name , first(start_date) as start_date , max(end_date) as end_date , count(*) as jobs pattern ( adjoin_or_overlap* last_row ) define adjoin_or_overlap as next(start_date) <= max(end_date) ) order by emp_id, start_date;Explanation of the pieces of that query:
- We go back to ordering by START_DATE.
- The definition checks if START_DATE of the next row is less than or equal to the highest END_DATE seen so far in the match – including the current row, because the MAX call will assume the current row is part of the match when it is evaluated. That means that when a row is classified as ADJOIN_OR_OVERLAP, that row should be merged with the next row.
- The pattern looks for zero or more ADJOIN_OR_OVERLAP rows followed by one single row classified LAST_ROW. As that classification is undefined, any row can match it - but since the row before LAST_ROW was classified ADJOIN_OR_OVERLAP, we know that the LAST_ROW should be merged too.
- If I find no ADJOIN_OR_OVERLAP rows, the row will become classified LAST_ROW because of the * in the pattern that says that zero ADJOIN_OR_OVERLAP rows are acceptable in the pattern. This means that when a row is not overlapping with any other rows, it will become a match of a single row classified as LAST_ROW and thus unmerged be part of the output.
- The measure END_DATE is calculated as the largest END_DATE of the match. Because we are not qualifying the END_DATE in the MAX call with either ADJOIN_OR_OVERLAP or LAST_ROW, MAX here is applied to all rows of the match no matter what classification the rows got.
The output of the query above is much improved, but still not quite correct.
Firstly several of the employees (including Mogens Juel) have a wrong value in the measure END_DATE. Those that are still employed should have NULL in the END_DATE column, and in this output that is only true for those with just a single hire period. For those that have had more than one job, the highest non-null END_DATE is wrongly displayed.
Secondly notice that Zoe Thorston also has overlapping rows – the problem here is just that the END_DATE of both rows are NULL, meaning both rows are current and she has both job functions. With the NULL values, the simple comparison to MAX(END_DATE) will not be true.
Both of these problems are because we are not handling the NULL values in END_DATE. This we will do now.
In this table we have set START_DATE to NOT NULL, but for the sake of being complete, let us pretend it could include NULL.
- So NULL in START_DATE (if we had allowed it) means the employee was employed since the Big Bang at the beginning of time.
- And NULL in END_DATE means the employee is employed until the end of time (or at least until someone updates the column with a non-null value ;-).
We cannot simply use IS NULL logic, as we want MAX to consider a NULL to be higher than any date. So instead we just change the definition to use NVL on both START_DATE and END_DATE, turning NULL in START_DATE into -4712-01-01 (smallest possible DATE in Oracle) and NULL in END_DATE into 9999-12-31 (highest possible DATE in Oracle).
Similarly in the calculation of the END_DATE measure, we use NVL in the MAX call to turn NULL in END_DATE into 9999-12-31, and then if the MAX does return 9999-12-31, we use NULLIF to turn that back into a NULL again.
select emp_id , name , start_date , end_date , jobs from emp_hire_periods match_recognize ( partition by emp_id order by start_date nulls first, end_date nulls last measures max(name) as name , first(start_date) as start_date , nullif( max(nvl(end_date, date '9999-12-31')) , date '9999-12-31' ) as end_date , count(*) as jobs pattern ( adjoin_or_overlap* last_row ) define adjoin_or_overlap as nvl(next(start_date), date '-4712-01-01') <= max(nvl(end_date, date '9999-12-31')) ) order by emp_id, start_date;This is a somewhat tricky MATCH_RECOGNIZE clause to understand, but it ends up giving us the desired merged date ranges.
You have seen that date comparison between rows in a pattern classification definition can "match up" periods for merging. Unlike how we grouped sequential numbers, this compares not simply to previous row, but to largest value of previous rows. This required us to reverse the logic and look ahead with NEXT.Tablespace growth spurts
The basis of this module is a table that every midnight samples the used space in each tablespace in the database. The dates are continuous (without gaps.)
select tabspace, sampledate, gigabytes from space order by tabspace, sampledate;We want to discover where there has been "spurts" of growth in a tablespace, but spurts can be two different things - either a "fast" spurt where a tablespace grew at least 25% in a single day, or a "slow" spurt where the tablespace grew between 10% and 25% every day for at least 3 days.
As the samples are at midnight, if we compare the value of the current row with the value of the next row, we get the growth for the current day. This is easily accomplished in the DEFINE clauses by using the NEXT function to read the gigabyte values of the next row (= next date). So we create two classifiers, FAST and SLOW, each with a formula that fits the growth percentage we want to search for. Then in the PATTERN clause we use the operator | which means OR, so that we search for a pattern of either one or more FAST rows or three or more consecutive SLOW rows.
select tabspace, spurttype, match_no, sampledate, gigabytes , end_of_day_gb, end_of_day_gb - gigabytes as growth , round(100 * (end_of_day_gb - gigabytes) / gigabytes, 1) as pct from space match_recognize ( partition by tabspace order by sampledate measures classifier() as spurttype , match_number() as match_no , next(gigabytes) as end_of_day_gb all rows per match after match skip past last row pattern ( fast+ | slow{3,} ) define fast as next(fast.gigabytes) / fast.gigabytes >= 1.25 , slow as next(slow.gigabytes) / slow.gigabytes >= 1.10 and next(slow.gigabytes) / slow.gigabytes < 1.25 ) order by tabspace, sampledate;Having observed with ALL ROWS PER MATCH that the pattern gives us what we want, we can now transform it to ONE ROW PER MATCH to get a simpler output for our growth spurt report.
Note in particular here, that in ONE ROW PER MATCH output, aggregates and PREV/NEXT functions get their values from the last row of the match. When we use ALL ROWS PER MATCH we could get the same value for DAYS by using FINAL COUNT(*), since FINAL keyword specifies to get the last (final) value. But if we tried FINAL NEXT(gigabytes) we would have gotten an error, as the combination of FINAL and NEXT is for some reason not allowed. However, here in a ONE ROW PER MATCH output, we can achieve the result as if we had used FINAL NEXT, since the NEXT is from the last row and therefore in effect FINAL (just without FINAL keyword.)
select tabspace, spurttype, startdate, startgb, enddate, endgb, days , (endgb - startgb) / days as avg_growth , round(100 * ((endgb - startgb) / days) / startgb, 1) as avg_pct from space match_recognize ( partition by tabspace order by sampledate measures classifier() as spurttype , first(sampledate) as startdate , first(gigabytes) as startgb , last(sampledate) as enddate , next(gigabytes) as endgb , count(*) as days one row per match after match skip past last row pattern ( fast+ | slow{3,} ) define fast as next(fast.gigabytes) / fast.gigabytes >= 1.25 , slow as next(slow.gigabytes) / slow.gigabytes >= 1.10 and next(slow.gigabytes) / slow.gigabytes < 1.25 ) order by tabspace, startdate;In the previous query we calculated the AVG_GROWTH and AVG_PCT columns in the SELECT list. But it is also allowed to put complex expressions in the MEASURES clause, so we could just as well place the calculations in the measures like this.
select tabspace, spurttype, startdate, startgb, enddate, endgb, days , avg_growth, avg_pct from space match_recognize ( partition by tabspace order by sampledate measures classifier() as spurttype , first(sampledate) as startdate , first(gigabytes) as startgb , last(sampledate) as enddate , next(gigabytes) as endgb , count(*) as days , (next(gigabytes) - first(gigabytes)) / count(*) as avg_growth , round(100 * ((next(gigabytes) - first(gigabytes)) / count(*)) / first(gigabytes), 1) as avg_pct one row per match after match skip past last row pattern ( fast+ | slow{3,} ) define fast as next(gigabytes) / gigabytes >= 1.25 , slow as next(slow.gigabytes) / slow.gigabytes >= 1.10 and next(slow.gigabytes) / slow.gigabytes < 1.25 ) order by tabspace, startdate;You have now seen how to use multiple classifiers and | (OR) in the expressions to search for multiple row patterns simultaneously, if what you are searching is multiple conditions.
Hierarchical child count
The basis of this module is the standard SCOTT.EMP table, where we want a hierarchical output with a column for each employee showing how many subordinates that employee has. With a scalar subquery we can find this with a fairly simple query.
select empno , lpad(' ', (level-1)*2) || ename as ename , ( select count(*) from emp sub start with sub.mgr = emp.empno connect by sub.mgr = prior sub.empno ) subs from emp start with mgr is null connect by mgr = prior empno order siblings by empno;But that requires accessing the table many times - not very efficient. We can make a much more efficient query using row pattern matching.
Since row pattern matching is very dependent on something to order the data by, we need to be able to preserve the hierarchical ordering for use in the MATCH_RECOGNIZE clause. For that purpose we create a subquery factoring WITH clause where we put the hierarchical query in an inline view, so we can use ROWNUM and give it an alias RN. This WITH clause will be the basis of our row pattern queries.
with hierarchy as ( select lvl, empno, ename, rownum as rn from ( select level as lvl, empno, ename from emp start with mgr is null connect by mgr = prior empno order siblings by empno ) ) select * from hierarchy order by rn;If we order the data by the hierarchy (order by rn) and start at any given employee, then following employees with a higher level are subordinates - until we reach a point where the level is the same or less. In MATCH_RECOGNIZE we use DEFINE to define a HIGHER row to be one where the level is greater than the starting row of the match. Then the pattern simply is that a given row must be followed by zero or more HIGHER rows. When we reach a row with the same or lower level than the starting row, the match stops.
Counting the number of HIGHER rows then is the number of subordinates we want. But once we've reached the end of the match, normally we'd search from there for a new match - in this case instead we want to go back to row after the beginning of the match and start searching for a new match from there. This is accomplished by AFTER MATCH SKIP TO NEXT ROW.
ALL ROWS PER MATCH allows us to see the details of each match in the output, so we can observe what actually is happening here.
with hierarchy as ( select lvl, empno, ename, rownum as rn from ( select level as lvl, empno, ename from emp start with mgr is null connect by mgr = prior empno order siblings by empno ) ) select match_no, rn , empno, lpad(' ', (lvl-1)*2) || ename as ename , rolling_cnt, subs, class , strt_no, strt_name, high_no, high_name from hierarchy match_recognize ( order by rn measures match_number() as match_no , classifier() as class , strt.empno as strt_no , strt.ename as strt_name , higher.empno as high_no , higher.ename as high_name , count(higher.lvl) as rolling_cnt , final count(higher.lvl) as subs all rows per match after match skip to next row pattern ( strt higher* ) define higher as higher.lvl > strt.lvl ) order by match_no, rn;Just as a visual aid, we can take the match numbers of the previous query and PIVOT it to visualize which rows are in match number 1, which are in match number 2, and so on.
with hierarchy as ( select lvl, empno, ename, rownum as rn from ( select level as lvl, empno, ename from emp start with mgr is null connect by mgr = prior empno order siblings by empno ) ) select rn, empno, ename , case "1" when 1 then 'XX' end "1" , case "2" when 1 then 'XX' end "2" , case "3" when 1 then 'XX' end "3" , case "4" when 1 then 'XX' end "4" , case "5" when 1 then 'XX' end "5" , case "6" when 1 then 'XX' end "6" , case "7" when 1 then 'XX' end "7" , case "8" when 1 then 'XX' end "8" , case "9" when 1 then 'XX' end "9" , case "10" when 1 then 'XX' end "10" , case "11" when 1 then 'XX' end "11" , case "12" when 1 then 'XX' end "12" , case "13" when 1 then 'XX' end "13" , case "14" when 1 then 'XX' end "14" from ( select match_no, rn, empno , lpad(' ', (lvl-1)*2) || ename as ename from hierarchy match_recognize ( order by rn measures match_number() as match_no all rows per match after match skip to next row pattern ( strt higher* ) define higher as higher.lvl > strt.lvl ) ) pivot ( count(*) for match_no in ( 1,2,3,4,5,6,7,8,9,10,11,12,13,14 ) ) order by rn;So if we change to using ONE ROW PER MATCH, we can get an output just like the original scalar subquery based query shown in the beginning of the module. But this query does not access the table multiple times - for larger datasets this scales much better and uses far fewer ressources.
with hierarchy as ( select lvl, empno, ename, rownum as rn from ( select level as lvl, empno, ename from emp start with mgr is null connect by mgr = prior empno order siblings by empno ) ) select empno , lpad(' ', (lvl-1)*2) || ename as ename , subs from hierarchy match_recognize ( order by rn measures strt.rn as rn , strt.lvl as lvl , strt.empno as empno , strt.ename as ename , final count(higher.lvl) as subs one row per match after match skip to next row pattern ( strt higher* ) define higher as higher.lvl > strt.lvl ) order by rn;Of course even when using ONE ROW PER MATCH we can still include more data if we wish, using FIRST or LAST or aggregate functions, like demonstrated here with MAX.
with hierarchy as ( select lvl, empno, ename, rownum as rn from ( select level as lvl, empno, ename from emp start with mgr is null connect by mgr = prior empno order siblings by empno ) ) select empno, lpad(' ', (lvl-1)*2) || ename as ename , subs, high_from, high_to, high_max from hierarchy match_recognize ( order by rn measures strt.rn as rn , strt.lvl as lvl , strt.empno as empno , strt.ename as ename , count(higher.lvl) as subs , first(higher.ename) as high_from , last(higher.ename) as high_to , max(higher.lvl) as high_max one row per match after match skip to next row pattern ( strt higher* ) define higher as higher.lvl > strt.lvl ) order by rn;It could be that we only want to output those employees that have subordinates. One way could be to put the query above in an inline view and filter on "subs > 0", but a simpler method is to simply change the PATTERN clause. If we change HIGHER* to HIGHER+, we indicate that a match only can be found if there is at least one HIGHER row, which means at least one subordinate.
with hierarchy as ( select lvl, empno, ename, rownum as rn from ( select level as lvl, empno, ename from emp start with mgr is null connect by mgr = prior empno order siblings by empno ) ) select empno , lpad(' ', (lvl-1)*2) || ename as ename , subs from hierarchy match_recognize ( order by rn measures strt.rn as rn , strt.lvl as lvl , strt.empno as empno , strt.ename as ename , count(higher.lvl) as subs one row per match after match skip to next row pattern ( strt higher+ ) define higher as higher.lvl > strt.lvl ) order by rn;Here you have seen a use case for AFTER MATCH SKIP TO NEXT ROW - a clause that not often is used, so can be easy to forget. But if you have a use case for it, it is highly efficient.
Bin fitting with limited kapacity
The basis of this module is a table with results of scientific studies of "sites" (like genomes or similar). Our task is assign the study sites to groups in such a manner, that the sum of the CNT column does not exceed 65000 - but the sites in each group has to be consecutive. In other words we need to perform a rolling sum of CNT in order of STUDY_SITE, but stop the rolling sum at the row before it exceeds 65000. Let us try a simple analytic rolling sum.
select study_site, cnt , sum(cnt) over ( order by study_site rows between unbounded preceding and current row ) as rolling_sum from sites order by study_site;We can spot that at site 1023 the rolling sum is 73946, which is too much, so our first group (bin) will have to be from site 1001 to site 1022, and then the rolling sum will have to be restarted from site 1023 so we can begin "filling a new bin".
The analytic sum cannot be "restarted" like that, but pattern matching can do it. Here we make a definition of classifier A that a row is classified A as long as the sum of all the rows in the match so far (including the current row) is less than or equal to 65000. The pattern simply states that a match is one or more consecutive rows classified A. So the rolling sum will continue up to site 1022, then in site 1023 the row will no longer be classified as an A row, so the match stops. With AFTER MATCH SKIP PAST LAST ROW, a new match is then started at the next row after the last row of the previous match, so the new match starts at site 1023. With ALL ROWS PER MATCH we can see how the rolling sum restarts whenever needed, so the MATCH_NO identifies which "bin" we group the rows in.
select study_site, cnt, rolling_sum, match_no from sites match_recognize ( order by study_site measures sum(cnt) rolling_sum , match_number() match_no all rows per match after match skip past last row pattern ( a+ ) define a as sum(cnt) <= 65000 ) order by study_site;Of course we could then group by MATCH_NO to get the set of "bins" and which sites go where, but we can easily get the same result by changing the query to use ONE ROW PER MATCH and then use aggregates in the MEASURES clause.
select first_site, last_site, cnt_sum from sites match_recognize ( order by study_site measures first(study_site) first_site , last(study_site) last_site , sum(cnt) cnt_sum one row per match after match skip past last row pattern ( a+ ) define a as sum(cnt) <= 65000 ) order by first_site;In the previous modules, formulas in DEFINE have accessed the current row, the previous row, following row, first row, or some combination thereof. In this module you have now learned that the DEFINE clause can contain aggregates too, just like MEASURES, enabling you to define a row classification based on data from a whole set of rows.
Bin fitting with fixed number of bins
The basis of this module is a simple table of items with a certain value (indicating for example weight or volume or some other measure).
select * from items order by item_value desc;We have 3 bins that we want to fill as equally as possible - meaning that the sum of the item values in each bin should be as near equal as we can get it. There is a fairly simple algorithm for this purpose:
- First, order the items by value in descending order.
- In that order, assign each item to whatever bin has the smallest sum so far.
In the following MATCH_RECOGNIZE clause we accomplish this with the use of the OR operator | to define a pattern, that matches zero or more occurences of either a BIN1 row or a BIN2 row or a BIN3 row.
So when a row is examined to find out which classifier the row matches, it will first try to find out if it matches the definition of BIN1. When testing if it matches, it is always assumed that it does, which means that in the formula used in the BIN1 definition, the COUNT and SUM will include the row we are testing to find out if it is a BIN1 row or not. So when we test COUNT(bin1.*) = 1, we actually test will this row be the first row in BIN1. Similarly, the SUM(bin1.item_value) is the sum of all BIN1 rows, which includes this row, so we need to subtract this row from the sum to get sum of all the previous rows. That way we can test if the sum of all previous rows in BIN1 is less than or equal to the smallest of the sums of BIN2 and BIN3 - if it is, then BIN1 is the bin with the smallest sum so far, so the row will be assigned to BIN1.
If the row was not assigned to BIN1, then BIN1 was not the bin with the smallest sum so far. Then we test for BIN2 if the row would be the first row in BIN2 or if the sum of previous rows in BIN2 is smaller than or equal to the BIN3 sum - if yes, then BIN2 is the the bin with the smallest sum so far, so we assign the row to BIN2.
if the row was not assigned to BIN2, then it must go in BIN3. We do not need to do any define for BIN3, as any classification used in the PATTERN but not defined in DEFINE is automatically true for any row (if the row has not matched any of the other defined classifications.)
As we defined the pattern with the * meaning zero or more occurences, the match will actually continue and include all the rows in a single match (so in a sense we are not really "searching for a pattern", as the pattern matches all rows.) But doing that allows the running COUNT and SUM in the DEFINE clauses to keep adding to the running totals all the way to the last row.
select item_name, item_value, bin#, bin1, bin2, bin3 from items match_recognize ( order by item_value desc measures to_number(substr(classifier(),4)) bin#, sum(bin1.item_value) bin1, sum(bin2.item_value) bin2, sum(bin3.item_value) bin3 all rows per match pattern ( (bin1|bin2|bin3)* ) define bin1 as count(bin1.*) = 1 or sum(bin1.item_value) - bin1.item_value <= least(sum(bin2.item_value), sum(bin3.item_value)) , bin2 as count(bin2.*) = 1 or sum(bin2.item_value) - bin2.item_value <= sum(bin3.item_value) );With a little bit of simplification, the output gives us very easily the result of which items are distributed in each bin.
select bin#, item_value, bin_total, item_name from items match_recognize ( order by item_value desc measures to_number(substr(classifier(),4)) bin# , case classifier() when 'BIN1' then final sum(bin1.item_value) when 'BIN2' then final sum(bin2.item_value) when 'BIN3' then final sum(bin3.item_value) end bin_total all rows per match pattern ( (bin1|bin2|bin3)* ) define bin1 as count(bin1.*) = 1 or sum(bin1.item_value) - bin1.item_value <= least(sum(bin2.item_value), sum(bin3.item_value)) , bin2 as count(bin2.*) = 1 or sum(bin2.item_value) - bin2.item_value <= sum(bin3.item_value) ) order by bin#, item_value desc;We can observe that the match actually includes all the rows if we change ALL ROWS PER MATCH to ONE ROW PER MATCH. But then we lose information which items are in each bin.
select * from items match_recognize ( order by item_value desc measures sum(bin1.item_value) bin1_total, sum(bin2.item_value) bin2_total, sum(bin3.item_value) bin3_total one row per match pattern ( (bin1|bin2|bin3)* ) define bin1 as count(bin1.*) = 1 or sum(bin1.item_value) - bin1.item_value <= least(sum(bin2.item_value), sum(bin3.item_value)) , bin2 as count(bin2.*) = 1 or sum(bin2.item_value) - bin2.item_value <= sum(bin3.item_value) );You now know that not just the patterns may be complex in row pattern matching - the DEFINE clause can also incorporate a logic in them with a higher complexity than merely comparing values. With techniques like this, you can make your row pattern matching solve very complex problems.
In total in these modules you have seen various examples of very different use cases for row pattern matching. It is a quite different way of thinking, but when you get into the habit, it can solve cases where even the use of analytic functions still make for complex queries. It can also be more efficient by being designed for working with multiple rows rather than one row at a time. When you learn the syntax you can write highly declarative analytic queries, where (if you choose good names in the DEFINE clause) you write the data patterns you search for almost in plain readable English.